vLLM+PyTorch Profiler性能分析
vLLM+PyTorch Profiler性能分析
1 使用 PyTorch Profiler 进行分析
vLLM 支持使用 torch.profiler 对工作进程进行跟踪。可以通过设置 VLLM_TORCH_PROFILER_DIR 环境变量来启用跟踪,将其指向希望保存跟踪文件的目录:VLLM_TORCH_PROFILER_DIR=/mnt/traces/。例如:
1
2
3
trace_dir = "/home/trace"
os.makedirs(trace_dir, exist_ok=True)
os.environ["VLLM_TORCH_PROFILER_DIR"] = trace_dir
在运行示例 python 文件时,可以手动开启/关闭 profiler:
1
2
3
llm.start_profile()
outputs = llm.generate(prompt, sampling_params)
llm.stop_profile()
会输出以下的分析结果:

2 使用 Perfetto 查看 trace
可以使用 Perfetto 查看 trace 文件。
把 profiler 生成的 trace 文件上传到 https://ui.perfetto.dev/ 网站,可以更清楚的观察每个 stream/thread 的具体内容。
Perfetto 会把整个 track 拆成三种大的区域:
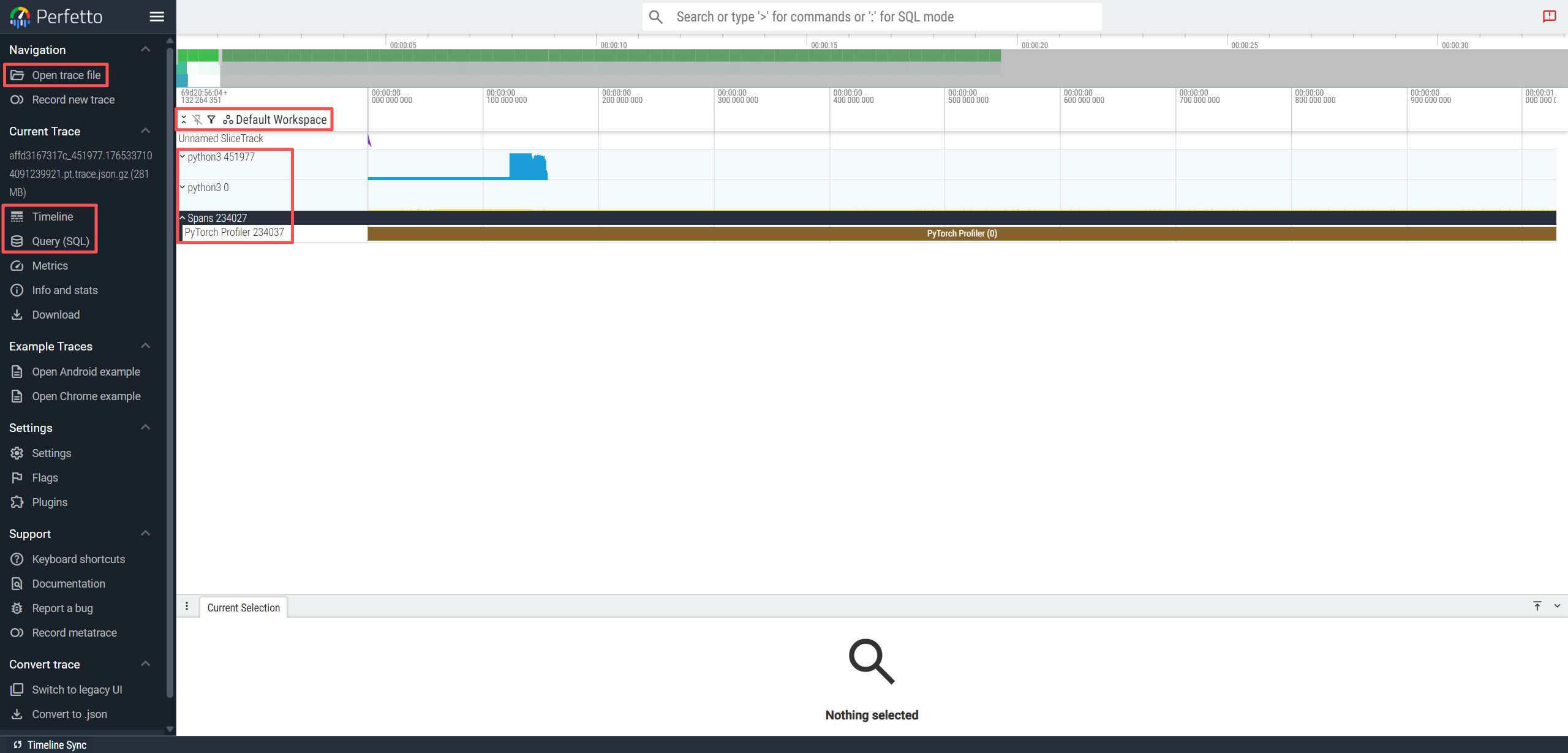
- CPU 区域
- 显示 Python 线程、vLLM Worker、Engine、网络 IO 线程等。例如在图中的 python3 423569、thread 423569 (python3) 等,都是 CPU 线程 Track。每一个彩色长条都是 CPU 执行的函数片段。
- 一般 vLLM 的 CPU 线程分工如下:
- Main Thread:负责 Python 层 dispatch、调用 engine、管理请求,执行用户脚本、生成 prompt、run 循环等。
- Scheduler Thread:负责决定每个请求用哪些 token、管理 batch、分配 compute 窗口。
- Engine Worker Threads:负责执行 KVCache load/save 操作(CPU 内部),会调用 CUDA kernels(会和 GPU 流关联)。
- vLLM Networking:例如 ZMQ Poll Thread
- GPU 区域:CUDA Streams
- stream 7 等等代表 GPU 上的 CUDA Streams,每个 stream 是 GPU 内部并行执行队列。
- 流编号不重要,但类别很重要:计算类 Kernel(MatMul、Softmax、Attention Kernels)、Memcpy / Memset(Load / Save 时特别关键)、NVTX 标记(带 M_ 这种字母)
- PyTorch Profiler
- 这是 PyTorch Profiler 的合成 Track,用来标记区间,基本不影响分析。
Perfetto 常用的缩放/移动操作:
- 缩放:把鼠标移到时间轴上,按住 Ctrl 再滚动鼠标滚轮可以放大/缩小。也可以用键盘 W(放大)/S(缩小)。
- 平移(左右移动时间轴):用键盘 A/D 向左/右平移;也可以按住 Shift 然后用鼠标拖拽来平移。按 E 可以把视图中心对准当前鼠标位置(快速跳到鼠标处)。
- 快速聚焦/框选缩放:在 overview(顶部小图)或者 timeline 上框选一个区域会放大到该范围(用鼠标拖选)。有些版本也支持用 M 键把当前选择框架化(frame selection)。
- 发现/搜索轨道:按 Ctrl+P 调出快速查找(fuzzy search),可以直接按名称找到想看的 track(进程/线程/流)。按 Ctrl+Shift+P 打开命令面板(Command Palette)。
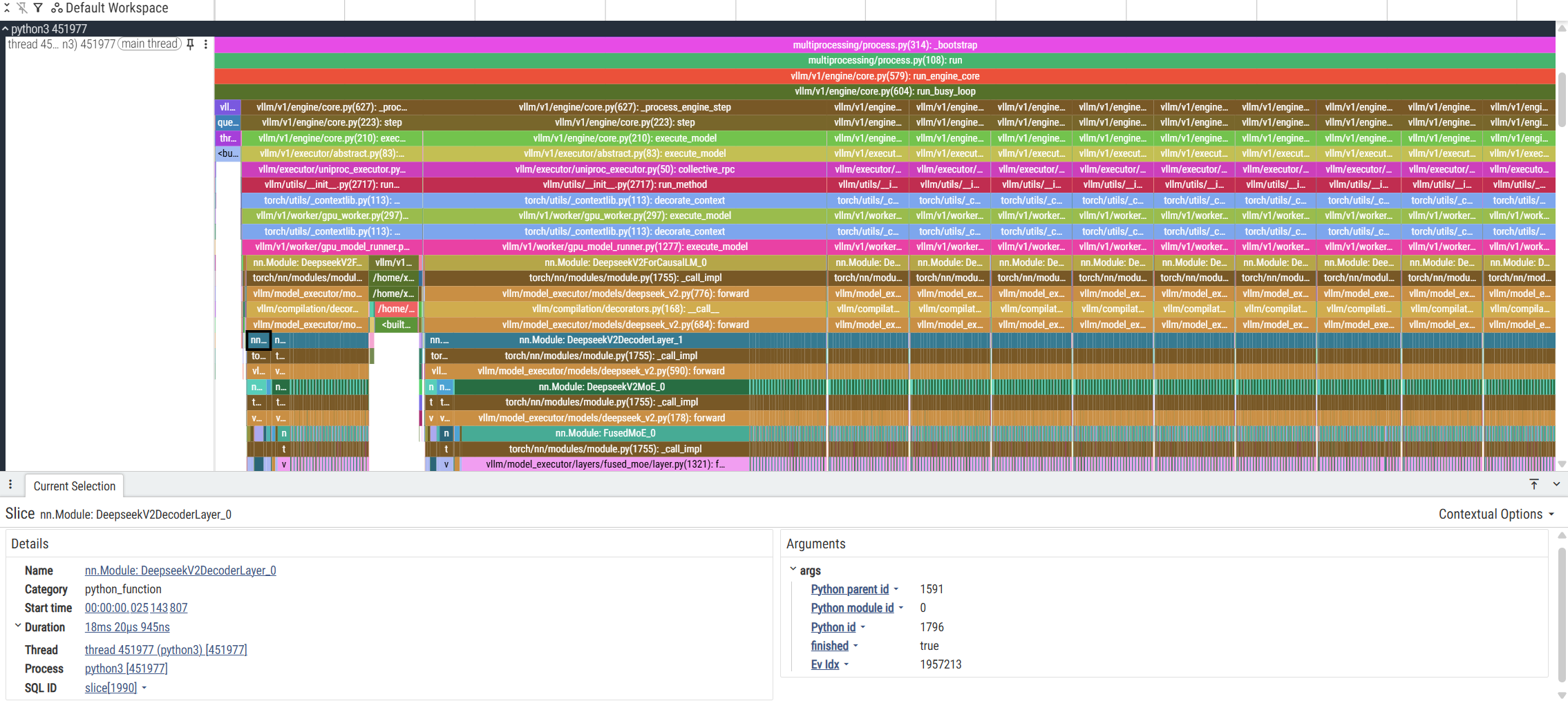
如何看清每个 stream / thread / track 是什么?
- 先在左侧的 track 列表找 track header(通常显示进程名 / 线程名 / PID / TID)。许多 trace 的 track header 就写明了进程名和线程名,点击 header 可以展开进程行,显示它的线程子轨道(process → threads)。
- 把鼠标移到某个 slice 上,会弹出 tooltip,显示该事件的 category、name、时间戳、持续时间、以及可能的 metadata(例如 trace event 的 args)。tooltip 是了解某个事件具体做了什么的第一手信息。
- 在 timeline 下方会有“Selection details / Track details”面板,选中一个 slice 后看详情里会列出更多字段(attributes、pid/tid、stack 等)。
- 如果事件跨线程(异步事件),Perfetto 会把关联的 async 事件通过 id 关联,你可以追踪这些 id 来看同一个逻辑在不同线程上如何分布(在 tooltip 或 selection details 里会有 async id/flow id 信息)。
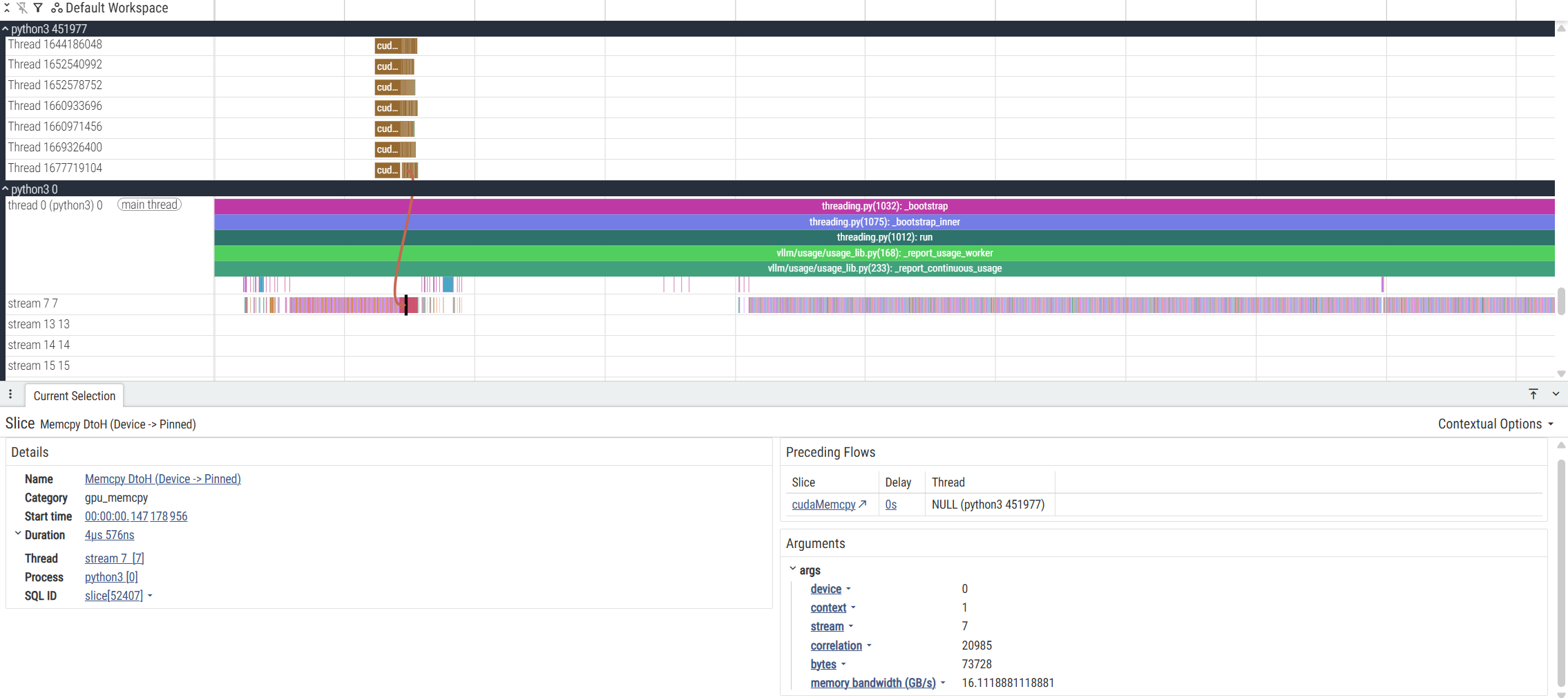

观察 trace 的其他技巧:
- 用 Ctrl+P 搜索 track 名、category 名或 slice 名(模糊匹配),能快速把目标 track 聚焦出来。
- 用 SQL 查询 trace(Perfetto 支持在 UI 里运行 SQL 查询 trace 数据模型),可以查 thread、process、sched_switch、track_event 等表来把 tid/pid/名字全部列出来。例如:
1
2
3
4
5
6
7
8
# 查询所有 CUDA kernels
SELECT * FROM slice WHERE category = "cuda";
# 搜索 memcpy 关键字
select ts, dur, name
from slice
where name like "%memcpy%"
order by ts;

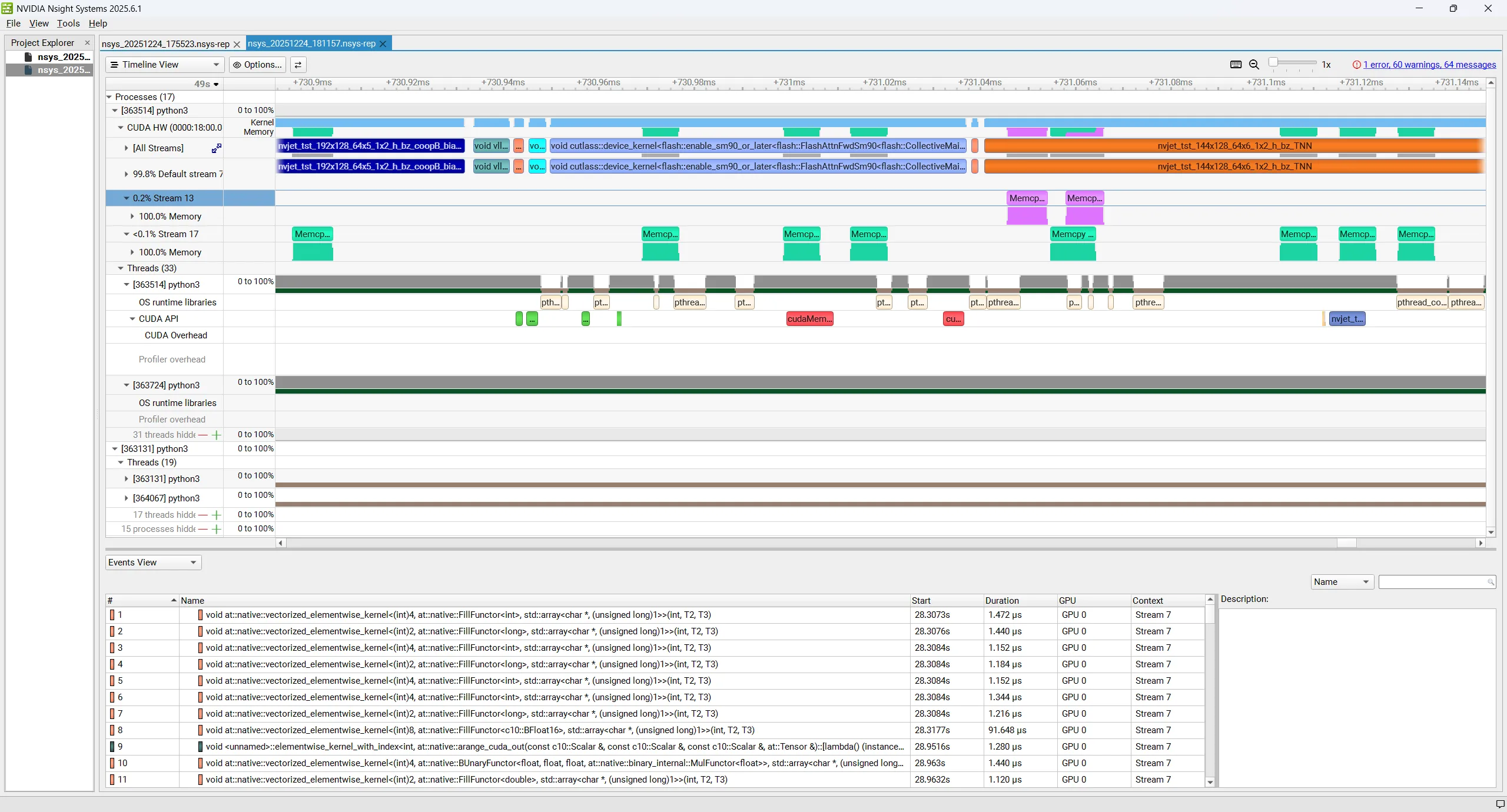
3 使用 Nsight Systems 进行分析
Nsight Systems 是一个高级工具,可以暴露更多的分析细节,例如寄存器和共享内存使用情况、注释的代码区域以及低级别的 CUDA API 和事件。
首先安装 nsight-systems,用以下命令运行得到 .nsys-rep 文件,然后在图像 UI 中查看并分析。如果包含子线程,需要使用 os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"。
1
2
3
nsys profile --output=/home/nsys_$(date +%Y%m%d_%H%M%S) \
--trace=cuda,nvtx,osrt --stats=true -f true \
python3 offline_inference.py
参考资料
This post is licensed under CC BY 4.0 by the author.