MOONCAKE论文阅读
本篇为论文 Mooncake: Trading More Storage for Less Computation — A KVCache-centric Architecture for Serving LLM Chatbot 的阅读笔记。
摘要
MOONCAKE 是 大语言模型聊天服务 Kimi 的推理平台,其核心任务是 高效地进行 LLM 请求的分布式推理调度与缓存管理。
1. 问题背景:
- 背景挑战:随着大语言模型(LLMs) 广泛应用,推理服务负载多样化,需要在满足复杂SLO约束的同时最大化吞吐量,直接影响收入。
- 资源解耦重构动机:prefill与decoding阶段具有不同计算特性,可分离部署。为提高资源利用率,必须将 GPU 集群中的 CPU、DRAM、SSD、RDMA 等可用但长期被低效闲置的资源,重新解耦为多个离散化资源池,分别优化不同阶段的需求。
2. 创新点:MOONCAKE 提出了一个以 KVCache 为中心(KVCache-centric)的解耦式(Disaggregated)架构,该架构的特点包括
解耦 prefill 与 decoding 阶段:将 prefill 与 decoding 分布在不同的 GPU 节点上;
异构资源复用:高效利用 GPU 集群中未被充分利用的 CPU、DRAM、SSD 和 RDMA 网络带宽,建立一个分布式 KVCache 系统;
全局调度器与缓存调度系统:核心调度器在满足延迟 SLO(服务等级目标)的前提下,调度 KVCache 缓存与请求处理任务,最大化系统吞吐量。
1 问题定义
1. LLM 推理的两阶段架构
- Prefill 阶段:并行处理所有输入 tokens,进行全量计算,生成中间KVCache;服务目标(SLO):首次 token 时间(TTFT)
- Decoding 阶段:使用 KVCache 自回归地生成后续 token;每个 batch 一次只生成一个 token;使用Continuous Batching(连续批处理)优化;服务目标(SLO):Token 间隔时间(TBT)
2. 优化目标:Goodput(有效吞吐量)
- 在满足 TTFT 和 TBT 的前提下,最大化系统处理的请求数量,确保资源利用与用户体验的平衡。
3. 核心思想:以存储换取计算效率
尽管已有工作尝试将 KVCache 缓存在本地,以重用前缀匹配的结果,但本地内存容量只能覆盖理论缓存命中率的约 50%。因此,需要设计分布式全局缓存机制来提高缓存复用率。
KVCache 的成本权衡
总 prefill 计算 FLOPS 公式为:
FLOPS(n) = l × (a·n²·d + b·n·d²)。复用长度为 p 的 KVCache 时,可节省的计算量为:l × (a·p²·d + b·p·d²)。KVCache 的传输大小(从远端缓存加载到 GPU HBM)为:
size = p × l × (2·d / gqa) × sKVCache 复用在 TTFT 上有利的条件为:
B / G > (2·d·s / gqa) × (a·p·d + b·d²)。- 左边是单位 FLOPS 所需带宽,右边是复用
p个 token 时,每节省一个 FLOP 所需的 KVCache 传输大小。若左边大于右边,即意味着传输缓存所需的带宽“划算”,就值得复用 KVCache。
- 左边是单位 FLOPS 所需带宽,右边是复用
2 MOONCAKE设计
2.1 总体框架
1. 架构核心思想:解耦 + 分布式缓存 + 全局调度
分离式架构。将单个 GPU 集群的资源打散并重新组织成三个可以独立弹性伸缩的资源池。其中 Prefill Pool 处理用户输入,主要对 TTFT 负责。Prefill 处理完之后对应的 KVCache 会被送到 Decode Pool 。虽然我们希望尽可能攒大的 batch 以提升 MFU,但这一部分主要需要对 TBT 负责。
- 解耦架构:将原先紧耦合的 GPU 节点拆分为 prefill 和 decoding 节点,将 GPU 集群中的 CPU、DRAM、SSD、RDMA 等资源组织为分布式 KVCache 存储体系。
- 核心调度器 Conductor:根据当前 KVCache 分布和系统负载,全局调度推理请求;
- MOONCAKE Store:分布在每个节点上,负责本地 KVCache 的管理与异步传输。
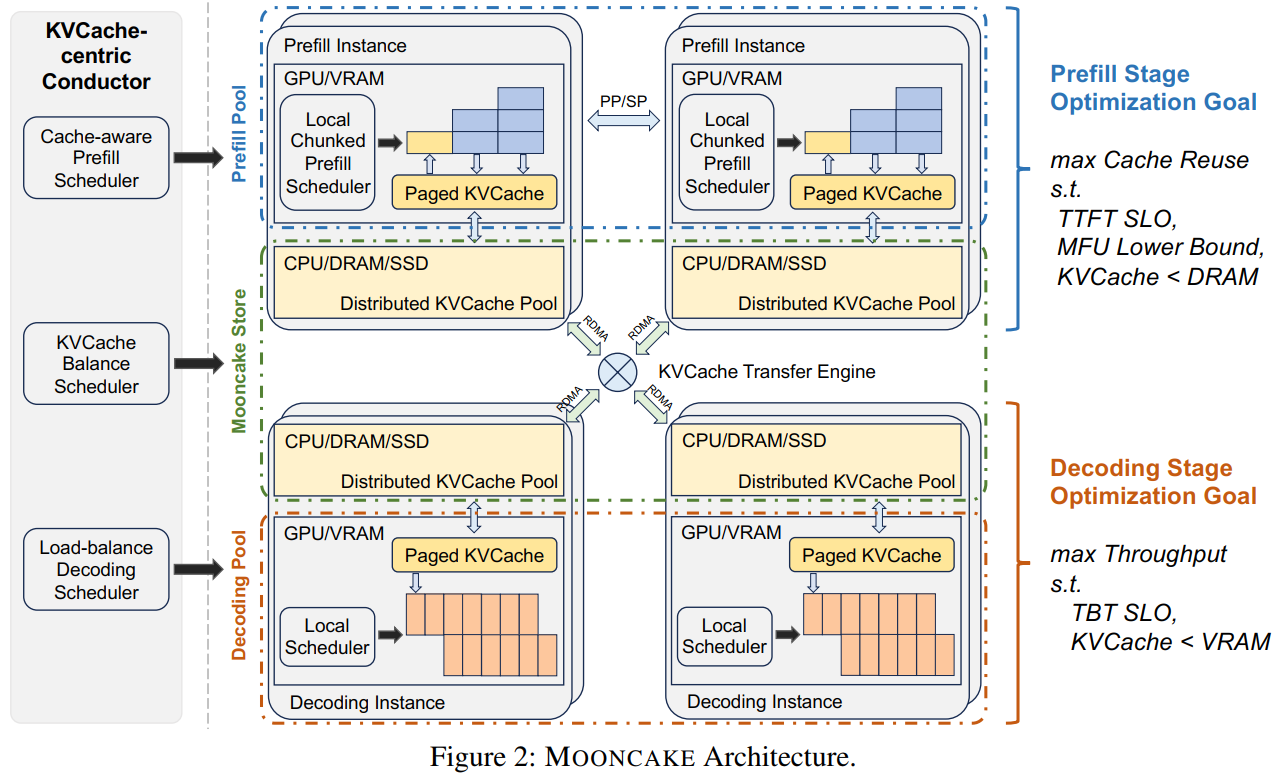
2. 推理请求的执行流程
KVCache复用:Conductor 将请求和可复用的前缀缓存块键一起下发到选定的 prefill 节点;节点根据这些键,将对应前缀的 KVCache 从远端 CPU 内存加载到本地 GPU HBM。调度目标三要素:尽可能复用已有 KVCache;平衡各 prefill 节点的负载;满足 TTFT。
增量 Prefill:prefill 节点根据剩余未命中的输入 token,完成增量计算并写入新的 KVCache;若未命中 token 较多,prefill 被分为多个小块执行,提升 GPU 利用率;该阶段产生的新 KVCache 写入本地 CPU 内存。
- KVCache 传输:使用 MOONCAKE Store 将生成的增量 KVCache 异步流式传输到目标 decoding 节点;与 prefill 阶段并行,减少拥塞与等待。
- 解码:当所有 KVCache 到位后,请求进入 decoding 节点的连续批处理队列;Conductor 预先选定的 decoding 节点会在不违背 TBT 的前提下,尽可能将新到请求并入批次,提升模型 FLOPs 利用率并快速生成后续 token。
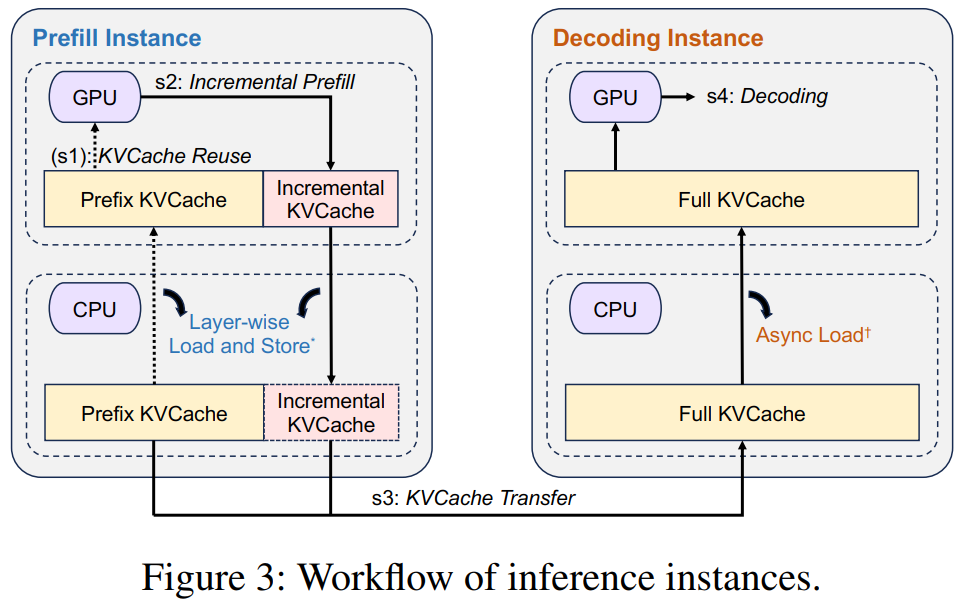
2.2 设计细节
1. KVCache 管理
- 存储形式:KVCache 被组织成 分页块,每块包含一定数量的 tokens,块大小取决于模型大小和网络传输效率。每个块由其自身哈希值和前缀哈希值生成的哈希键唯一标识,可用于去重。
- 副本机制:相同的 KVCache 块可能存在于多个节点中,降低热点访问延迟。
- 淘汰策略:LRU
2. Prefill Pool
- 为什么仍需独立的 Prefill Pool
- 解耦必要性:虽有“chunked prefill”能缓解部分解码干扰,但在线服务的 SLO 极为苛刻,难以靠单节点同时兼顾前填充高 MFU 和解码低延迟。
- 快速增长的上下文长度:当前 LLM 的上下文从 8K→128K 甚至 1M token,长上下文请求中输入远多于输出(10–100×),TTFT 优化尤为关键。
- Chunked Pipeline Parallelism (CPP) 方案
- 节点分组:将若干节点组成一个 pipeline prefill group;
- 请求切块:每个请求的输入 tokens 按
prefill_chunk大小切分为若干 chunk; - 流水线并行:不同 chunk 在同一组内的不同节点上并行处理;每个 chunk 在其 “stage” 完成后,通过少量跨节点通信传递中间数据,通信可与计算重叠。
- 优势:高 MFU、低网络争用;兼容各种上下文长度
3. Prefill Global Scheduling
- 传统做法仅根据每个 prefill 实例上挂载的请求数来均衡负载;MOONCAKE 在此基础上还考虑前缀缓存命中长度及可复用 KVCache 块的分布,实现“以 KVCache 为中心”的调度。
- 对每个新到请求,Conductor 会遍历各 prefill 实例的缓存块键,计算与请求前缀的最大匹配长度。基于离线采样数据,用多项式回归预测给定请求长度、最大前缀匹配长度下的 prefill 计算时长,与当前队列等待时间相加,得到请求在该实例上的预计 TTFT。Conductor 比较所有实例上的预计 TTFT,将请求分派给最小的 prefill 实例。
4. Cache Load Balancing
- 静态或基于历史的预测模型,对于随机变化的请求分布,难以准确预估未来缓存热度;
启发式热点迁移方案:计算从最优节点传输 KVCache 到当前节点的时间、当前节点重算前缀的额外 prefill 时间;若传输时间小于计算时间,则主动将缓存从远端拉到本地,并在本地建立副本;否则在本地直接计算,节省网络带宽。
- 好处:TTFT 更小;促使热点 KVCache 自动在多实例间多点复制,提升全局命中率。
3 实验评估
MOONCAKE 是否优于现有开源 LLM 推理系统(如 vLLM)?
MOONCAKE Store 的分布式缓存设计相较于传统本地前缀缓存,能否显著提升性能?
1. 工作负载
- Conversation:上下文长度最长可达 128 K tokens,平均约 12 K tokens;前缀缓存比例平均约 40%,得益于用户的多轮对话中大量重复上下文;
- Tool & Agent:通常带有固定、较长的系统提示;更高的前缀缓存比例;整体输入/输出长度较短,以快速任务执行为主。
- Synthetic:融合三类公开数据集,按 1:1:1 比例混合并打乱顺序;最长的平均输入长度;最高的前缀缓存需求,缓存命中分布分散。
2. 有效请求容量
Conversation 工作负载:KVCache-centric 解耦 + 分布式全局缓存显著提升缓存命中;请求容量比 vLLM 高出数倍。
Tool & Agent 工作负载:利用全局缓存池跨节点拉取 KVCache,大幅提升缓存利用;在 TBT ≤ 200 ms 下,有效容量比 vLLM+Prefix 高 42%。
Synthetic 合成工作负载:约 80% 请求 TBT 控制在 100 ms 以内;在 TBT ≤ 200 ms 条件下,有效请求容量比 vLLM 高 40%。
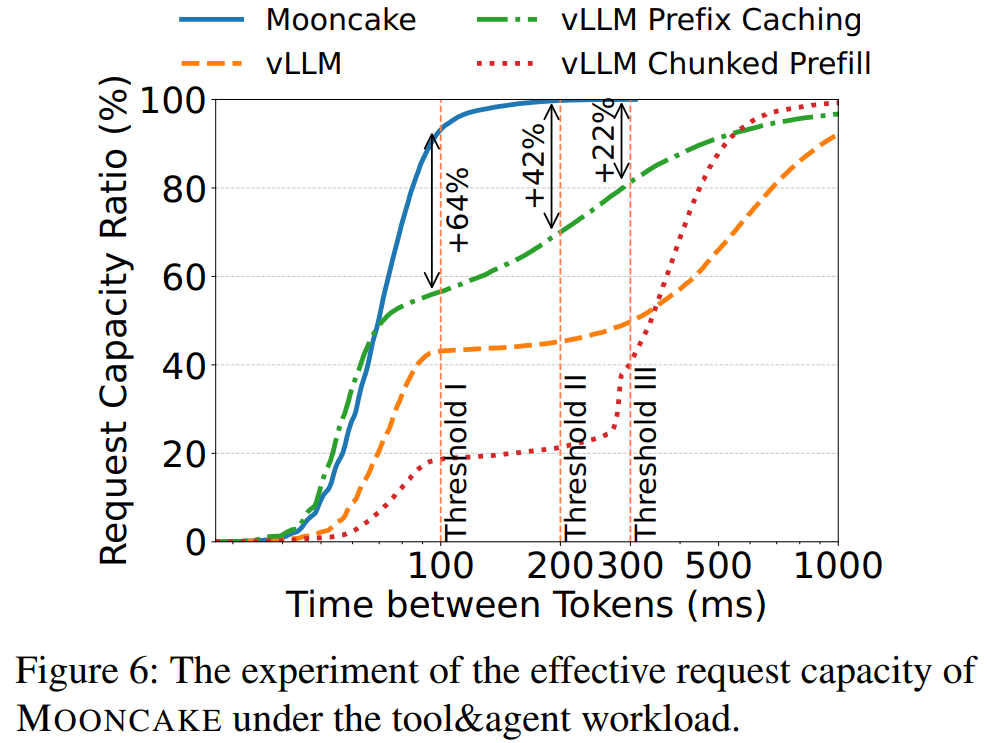
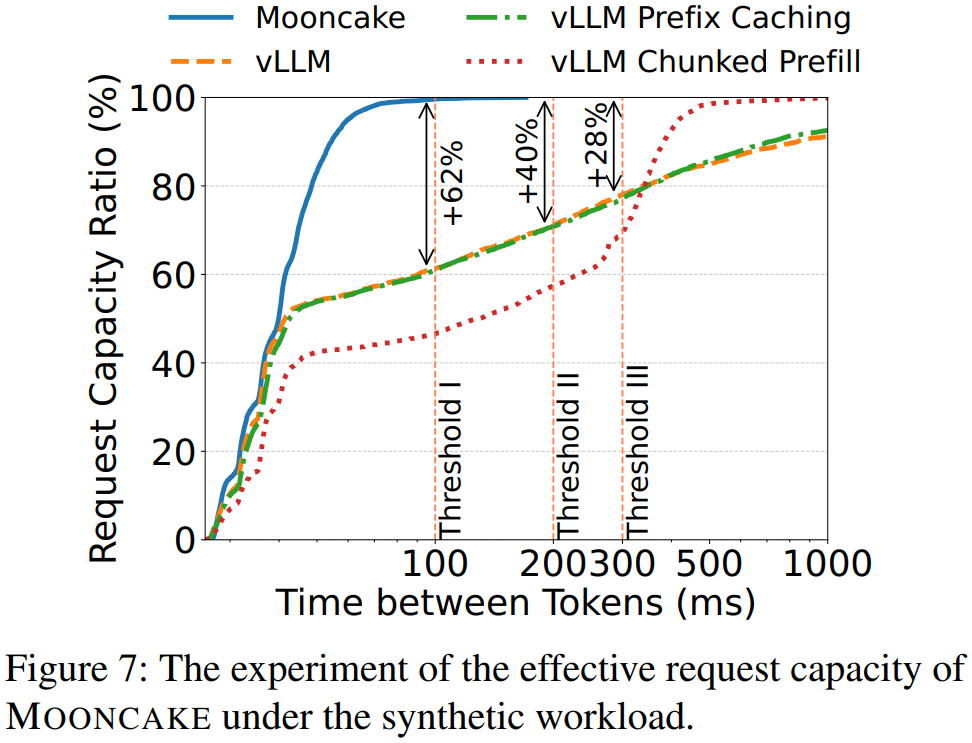
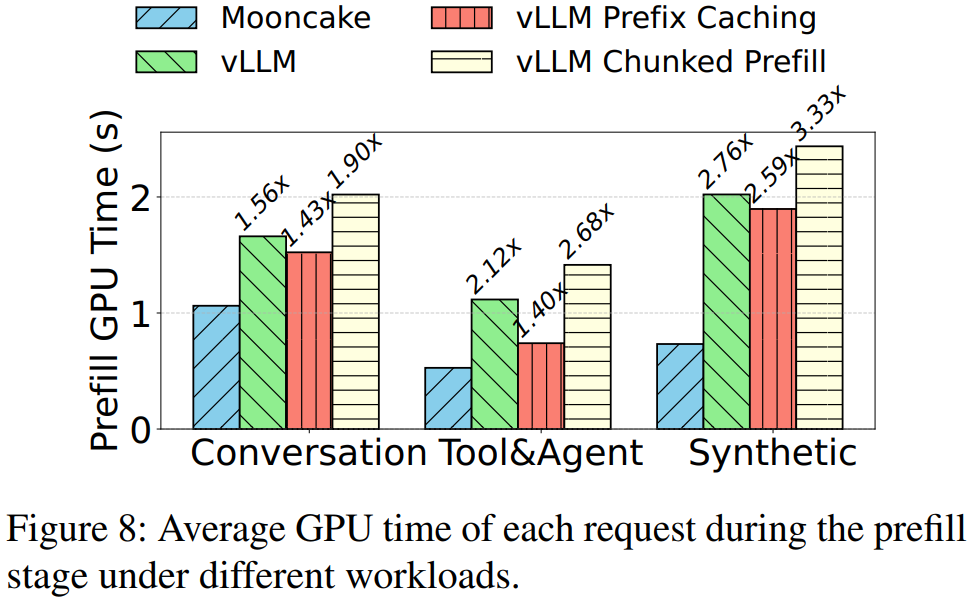
3. Prefill GPU 时间
Prefill 阶段的 GPU 时间越短,TTFT 越低,服务成本越小;其主要受输入长度和缓存命中率影响。
- MOONCAKE vs vLLM:MOONCAKE 利用全局 KVCache 完全复用前缀缓存,使 Prefill GPU 时间分别下降约36%(Conversation)、53%(Tool & Agent)、64%(Synthetic)
- vLLM + Prefix Caching:仅在本地 HBM 缓存,容量受限;Synthetic 较差,因热点分散,本地缓存失效
- vLLM + Chunked Prefill:为了保障 Decoding TBT 而牺牲 Prefill 效率,导致 Prefill 时间最长
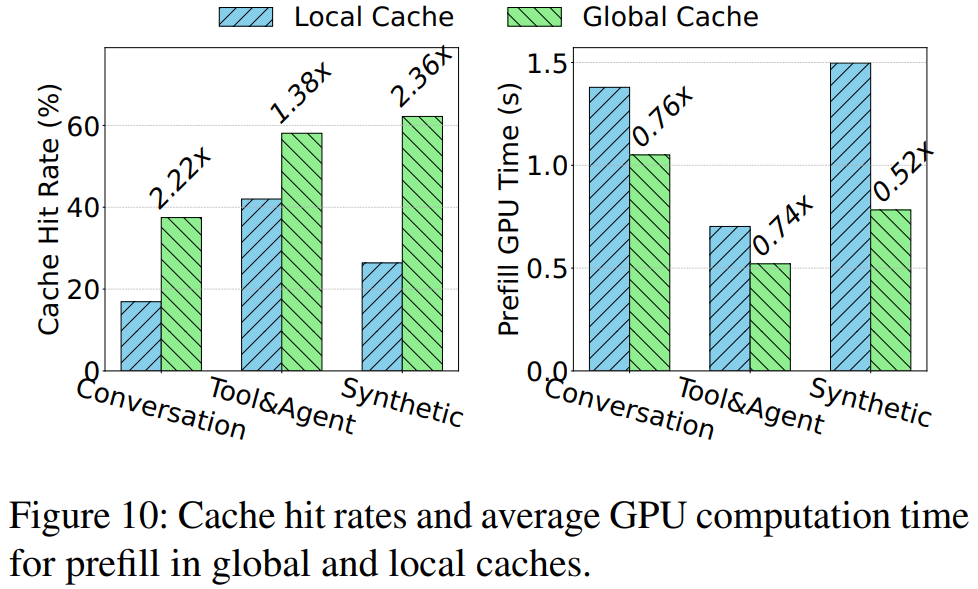
4. 实际负载对比实验
- 结果:全局缓存比本地缓存最高命中率提升 136%;Prefill 计算时间最多缩短 48%。
- 结论:全局池化 + 主动迁移策略显著提升了 KVCache 利用效率和计算性能。
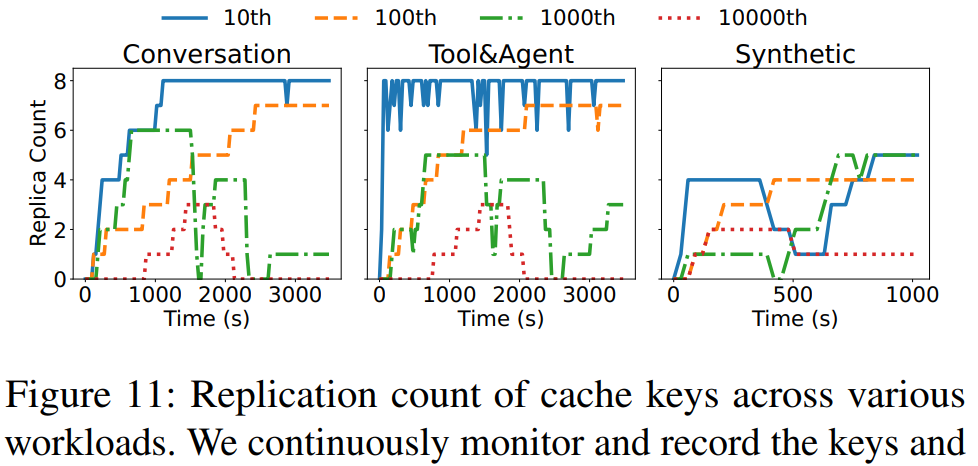
5. 缓存副本分布
- Conversation & Tool&Agent:前 100 个热点键几乎在所有 Prefill 实例上都有副本;
- Synthetic 负载:热点分散,前 10 个键的副本数也较少且波动较大。
- 意义:热点迁移策略能在集中型热点场景下快速复制关键 KVCache,提高全局命中;对于分散型热点,副本数受限,仍有优化空间。