LLM 和 KV cache 详解
1 从prompt到output
作为一种大型语言模型,LLaMA 的工作原理是接收输入文本(prompt),并预测下一个标记或单词。
举个例子。我们的 prompt 是:
1
Quantum mechanics is a fundamental theory in physics that
LLM 会根据它所接受的训练,尝试续写这个句子:
1
provides insights into how matter and energy behave at the atomic scale.
LLM 的核心是每次只预测一个 token。要生成一个完整的句子,需要对同一 prompt 重复应用 LLM 模型,并将之前的输出 token 附加到新的 prompt 中。这类模型被称为自回归模型(autoregressive)。
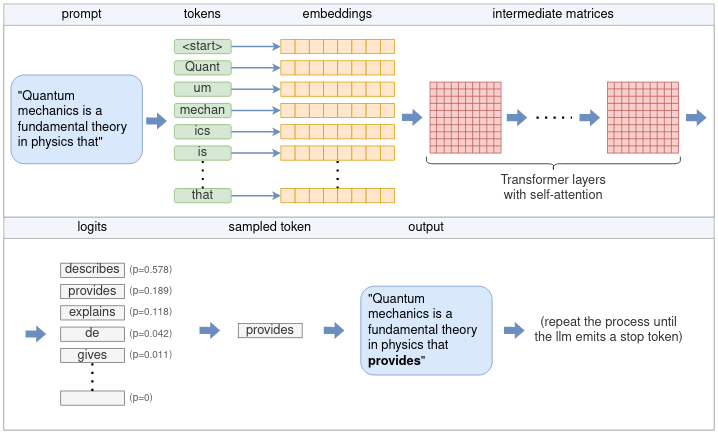
从用户 prompt 生成单个 token 的完整流程包括 tokenization、embedding、Transformer neural network 和 sampling 等阶段。按照图示,流程如下:
- tokenizer 将 prompt 分割成一系列 token。根据模型的词汇量,有些单词可能会被拆分成多个 token。每个标记由一个唯一的数字表示。
- 每个数字标记都会转换成一个 embedding。embedding 是一个固定大小的向量,它能以更有效的方式表示标记,以便 LLM 处理。所有的嵌入向量共同组成一个嵌入矩阵。
- 嵌入矩阵是 Transformer 的输入。Transformer 是一个神经网络,是 LLM 的核心,由多层链组成。每一层接收一个输入矩阵,并利用模型参数对其执行各种数学运算,其中最显著的是 self-attention mechanism。该层的输出被用作下一层的输入。
- 最后一个神经网络将 Transformer 的输出转换成对数。每个可能的下一个标记都有一个相应的 logit,代表该 token 是句子正确延续的概率。
- 从对数列表中选择下一个 token 时,会使用几种抽样技术中的一种。
- 被选中的标记作为输出返回。要继续生成标记,可将所选标记添加到步骤 1 的标记列表中,然后重复该过程。这个过程可以一直持续到生成所需的 token 数量,或者 LLM 发出一个特殊的流结束(EOS)token。
2 Tensor
Tensor 是一种通用的数据结构,它可以表示标量(0维)、向量(1维)、矩阵(2维)以及更高维度的数据。
2.1 计算张量
在许多深度学习框架中,执行计算和描述计算是两个不同的步骤。
- 执行计算(eager execution):立刻执行操作,得到结果。
- 描述计算(lazy execution):先把计算过程“描述”下来,之后再一次性执行。
以 LLM 为例,ggml_mul_mat() 等张量操作本质上不会立即执行计算,而是构建一个计算图,等待后面一次性执行计算。
计算图是一个有向无环图,每个节点代表一个张量操作,每个边代表一个张量(中间结果或输入)。
2.2 将计算卸载到 GPU
由于 GPU 的高度并行性,许多张量运算都可以在 GPU 上更高效地计算。
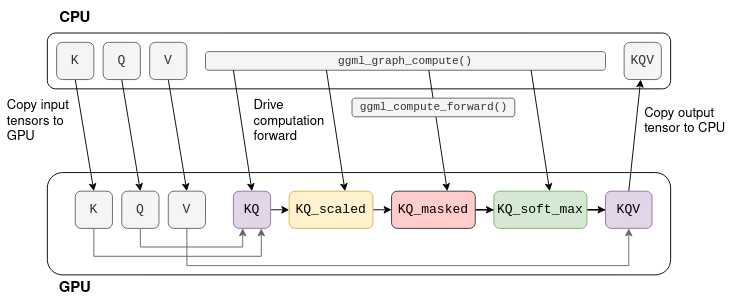
举个例子。假设 K、Q、V 是固定的张量,那么计算就可以卸载到 GPU 上:首先将 K、Q、V 复制到 GPU 内存中。然后,CPU 逐个张量驱动计算,但实际的数学运算则卸载到 GPU。当图形中的最后一个运算结束时,结果张量的数据将从 GPU 内存复制回 CPU 内存。
3 Tokenization
Tokenization 是将 prompt 拆分成一系列较短的字符串(token)的过程。这些 token 必须是模型词汇的一部分,也就是 LLM 所训练的 token 列表。
以 LLaMA 为例,标记化器是基于子词的,即单词可以由多个 token 来表示。在训练过程中,BPE 算法会确保常用词以单个 token 的形式包含在词汇中,而罕见词则被分解成子词。例如,“Quantum”一词不在词汇中,被拆分为 “Quant ”和 “um”。
Tokenization 过程首先将 prompt 分解成单字符 token。然后,它会反复尝试将每两个相应的 token 合并成一个更大的,只要合并后的 token 是词汇的一部分。这样可以确保生成的标记尽可能大。对于开头的例子,tokenization 步骤如下:
1
2
3
4
5
6
Q|u|a|n|t|u|m|▁|m|e|c|h|a|n|i|c|s|▁|i|s|▁a|▁|f|u|n|d|a|m|e|n|t|a|l|
Qu|an|t|um|▁m|e|ch|an|ic|s|▁|is|▁a|▁f|u|nd|am|en|t|al|
Qu|ant|um|▁me|chan|ics|▁is|▁a|▁f|und|am|ent|al|
Quant|um|▁mechan|ics|▁is|▁a|▁fund|ament|al|
Quant|um|▁mechan|ics|▁is|▁a|▁fund|amental|
Quant|um|▁mechan|ics|▁is|▁a|▁fundamental|
4 Embeddings
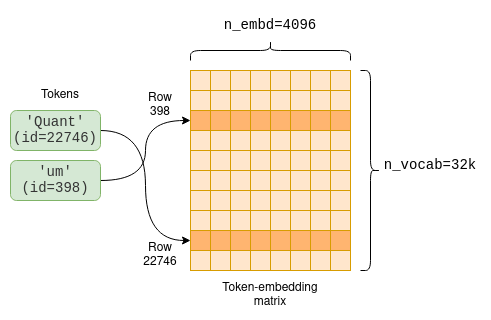
Embedding 是每个 token 的固定向量表示,它比纯整数更适合深度学习,因为它能捕捉词语的语义。这个向量的大小就是模型维度。例如,在 LLaMA-7B 中,模型维度为 n_embd=4096。
模型参数包括将标记转换为嵌入的标记嵌入矩阵(token-embedding matrix)。由于我们的词汇量为 n_vocab=32000,因此这是一个 32000 x 4096 的矩阵,每行包含一个标记的嵌入向量:
嵌入过程是计算图的第一部分。首先从标记嵌入矩阵中提取每个 token 的相关行;接着,用抽取的行创建一个新的 n_tokens x n_embd 矩阵,其中只包含按原始顺序排列的标记的嵌入式,就构成了 prompt 的嵌入矩阵:
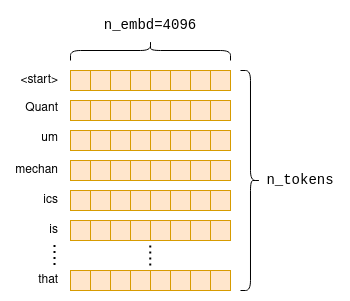
5 Transformer
计算图的主要部分称为 Transformer。它不是单个算法,而是由多层模块组成的结构化神经网络。Transformer 是 LLM 的核心,执行主要的推理逻辑。
5.1 Self-attention
Self-Attention(自注意力机制) 是 Transformer 的核心计算机制。它的作用是:输入一组 token 的 embedding ,输出每个 token 的上下文相关表示,即融合了其他 token 信息的向量。它是 LLM 架构中唯一计算 token 之间关系的地方,因此,它构成了语言理解的核心。
Self-Attention 的输入是 n_tokens x n_embd 嵌入矩阵,每一行代表一个独立的 token。然后,每个向量都被转换成三个大小为 n_tokens x n_embd 的向量 Q K V,分别称为 “key”、“query ”和 “value”。这种转换是通过将每个 token 的嵌入向量与固定的 wk、wq 和 wv 矩阵相乘来实现的,这些矩阵是模型参数的一部分:
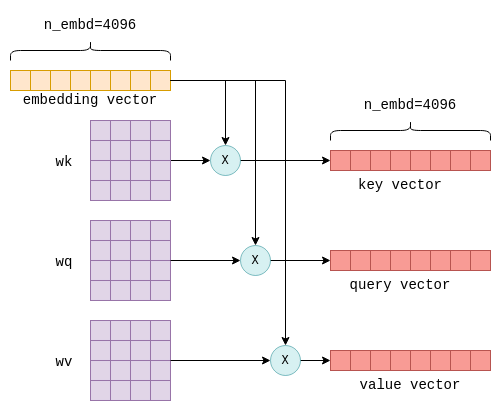
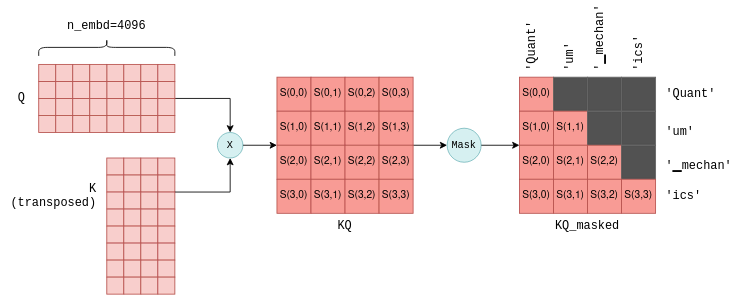
接下来是计算注意力分数。即将 Q 矩阵乘以 K 矩阵的转置,得到一个 n_tokens × n_tokens 的注意力得分矩阵(KQ 矩阵),S(i,j) 表示第 i 个 token 与第 j 个 token 的相关性。
得到注意力分数矩阵后要进行 mask 操作,即把矩阵中未来位置的值(对角线上方)置为负无穷,防止模型看到未来词。
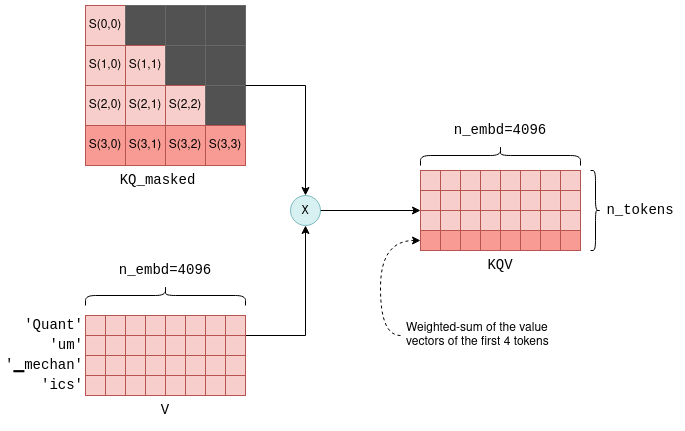
最后加权求和生成最终输出向量。将屏蔽后的注意力分数矩阵 KQ_masked 与 V 相乘,得到 KQV 矩阵。每一行是某个 token 融合上下文后的表示向量,即前面所有 token 的 V 向量加权求和,权重来自对应的注意力得分。这就是 Self-Attention 的输出,作为后续前馈神经网络的输入。
5.2 Transformer 的层次
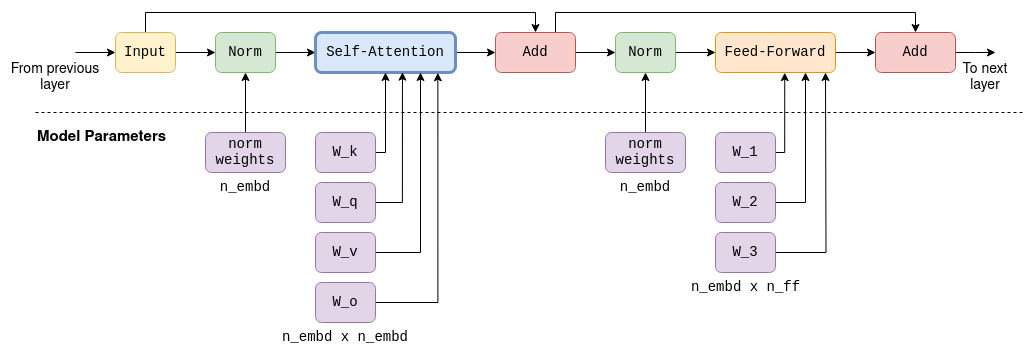
Transformer 并不是一个“单一结构”,而是由多个相同结构的层级联组成的神经网络。每一层包括两个主要部分:
- Self-Attention 机制:捕捉 token 之间的上下文关系(唯一一个跨 token 计算的模块)
- 前馈神经网络(Feed-Forward Network, FFN):对每个 token 进行进一步特征变换
需注意以下事实:
- 前馈网络中使用了大型固定参数矩阵,它们的大小为
n_embd x n_ff。 - 除了 self-attention 外,所有其他操作都是逐个 token 进行的,只有 self-attention 包含跨标记计算。这一点在讨论 kv-cache 时会很重要。
- 输入和输出的大小总是
n_tokens x n_embd: 每个 token 有一行,每行的大小与模型的维度相同。
以 LLaMA-7B 中单个 Transformer 层为例。包含自我关注和前馈机制,每一层的输出都是下一层的输入。自注意阶段和前馈阶段都使用了大量参数矩阵。
5.3 计算对数
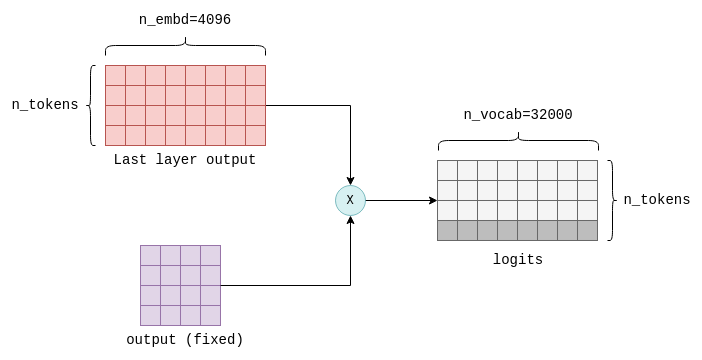
Transformer 的最后一步是计算对数。对数是一个浮点数,表示某个 token 是下一个 “正确 ” token 的概率。
对数值的计算方法是将最后一层变换器的输出与固定的 n_embd x n_vocab 参数矩阵相乘。只有结果的最后一行值得关注,它包含词汇表中每个可能的下一个 token 的对数。
6 KV cache
Transformer 的自注意力机制要在每一步都用当前 token 的 query 去跟所有 前面的 key 做打分,再去加权 前面的 value。这就意味着:
- 当前第 n 个 token 的 attention 需要用到第 1 到 n 个 token 的所有 key 和 value。
- 如果每次都重新计算前面的 k 和 v,就会非常浪费。而每个矩阵乘法都由许多浮点运算组成,受到 GPU 浮点运算秒容量(flops)的限制。
- 前面的 k 和 v 是不变的(不受后面的 token 影响),所以可以缓存下来,供下次使用。
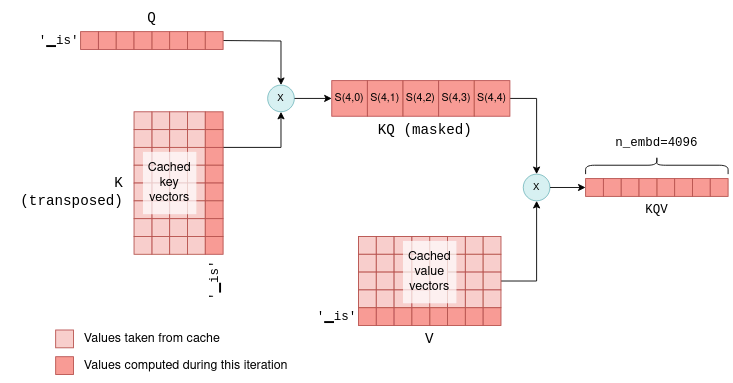
6.1 KV cache原理
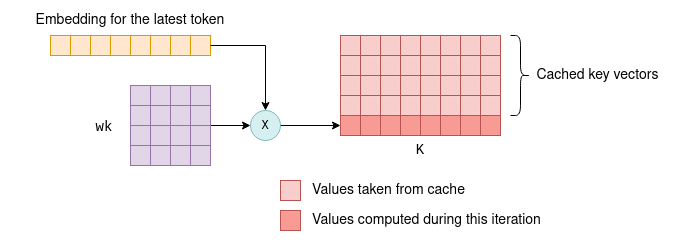
每个 token 都有一个相关的嵌入向量,通过与参数矩阵 wk 和 wv 相乘,进一步转化为键向量和值向量。kv cache 是这些键向量和值向量的缓存。通过缓存,我们可以节省每次迭代时重新计算所需的浮点运算。KV cache 的工作原理如下:
- 在初始迭代中,计算所有 token 的键和值向量,保存到 kv cache 中。
- 在随后迭代中,只需要计算最新 token 的键和值向量。缓存的 kv 向量和新标记的 kv 向量会连接在一起,形成
K和V矩阵。这样就省去了重新计算之前所有 token 的 kv 向量的过程。
6.2 为什么不缓存Q?
事实上,除了当前 token 的 Q 向量外,之前 token 的 Q 向量在后续迭代中是不必要的。在 Transformer 的每一层中,当前 token 的输出只依赖于:
- 当前 token 的
Q向量(新算的) - 所有 token 的
KV向量(前面的来自 cache,当前新算)