GPUDirect Storage(GDS)详解
1 GDS 原理简介
下图是从SSD向GPU传送资料的传统I/O路径,资料会经由PCIe交换器、经过主机CPU、复制,写入主机记忆体回弹缓冲区(bounce buffer),再经由CPU、PCIe交换器,复制写入GPU的记忆体,供GPU存取。这整个过程需要经过6个环节,以及2次资料复制作业。
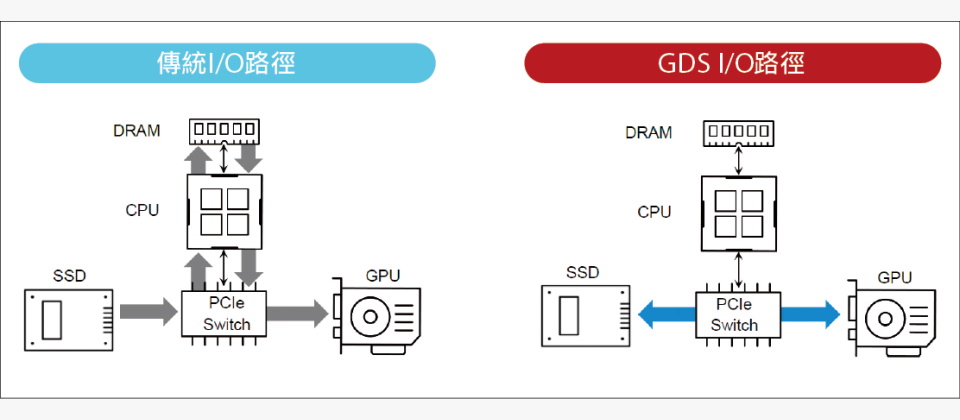
之所以必须采用这种繁琐的传输路径,是一系列原因造成的。
在储存装置与GPU之间的资料移动,是透过CPU运行的系统软体驱动程式来管理,并可由下列3种方式来执行传输作业,但各有限制:
- 经由GPU的直接记忆体存取(DMA)引擎执行资料传输工作,但是,第3方周边装置通常不会公开其记忆体给其他装置的DMA引擎定址,因而GPU无法以其DMA引擎直接存取第3方的周边装置,只有主机CPU的记忆体可供GPU DMA引擎存取。这也导致第3方周边装置向GPU的资料传输路径,必须经过主机CPU记忆体中的回弹缓冲区,来作为中介。
- 经由CPU的载入与储存指令来执行资料传输,但CPU无法在2个周边装置之间直接复制资料,而须经由CPU记忆体回弹缓冲区的中介。
- 经由周边装置的DMA引擎来执行资料传输,如NVMe SSD、网路卡或RAID卡的DMA引擎,而GPU的PCIe基底位址暂存器(PCIe Base Address Register,BAR)的定址,是可以提供给其他周边装置DMA引擎存取的,Nvidia的GPUDirect RDMA技术,就是利用这点来实现GPU与网路卡之间的直连存取。
问题在于,若存取的目标是档案系统层级的储存装置,就必须由作业系统介入存取过程,但作业系统并不支援将GPU的虚拟定址传递给档案系统,因而无法执行DMA存取。
传统I/O路径会带来下列3个副作用:
- 延迟增加;
- 传输效率受CPU的PCIe通道频宽限制;
- 传输作业需耗费CPU周期,增加CPU与主机记忆体负担,并与其他工作负载争抢CPU资源与主机记忆体频宽,导致传输率的抖动与不稳定。
上图是在GDS架构,从SSD向GPU传送资料的I/O路径,可以绕过(Bypass)主机CPU与记忆体,让SSD直接透过PCIe交换器,以DMA方式将资料复制写入GPU的记忆体,整个过程只需经过2个环节,以及1次资料复制,从而带来3项直接效益:
- 避开主机CPU的PCIe通道频宽限制;
- 减少传输过程的环节,降低延迟;
- 降低主机CPU与记忆体的负担,减少资料传输作业对于其他工作负载的影响。
2 GDS 的优势
使用 GPUDirect Storage 可以实现以下性能提升:
- 带宽:CPU 的 PCIe 进出带宽可能低于 GPU 的带宽能力。这种差异可能是由于服务器的 PCIe 拓扑结构导致 CPU 的 PCIe 路径较少造成的。位于同一 PCIe 交换机下的 GPU、网卡和存储设备通常会具有更高的 PCIe 带宽。使用 GPUDirect Storage (GDS) 可以缓解这些 CPU 带宽问题,尤其是在 GPU 和存储设备位于同一 PCIe 交换机下时。这提高了带宽,降低了延迟,并减少了 CPU 和 GPU 的吞吐量负载。此外,它还使靠近存储设备的 DMA 引擎能够将数据直接移动到 GPU 内存中。
- 延迟:使用反弹缓冲区会导致两次复制操作:将数据从源复制到反弹缓冲区;再次从反弹缓冲区复制到目标设备。直接数据路径只有一份数据副本,从源端到目标端。如果由 CPU 执行数据传输,则 CPU 可用性冲突可能会影响延迟,从而导致数据抖动。GDS 可以缓解这些延迟问题。
- CPU利用率:如果CPU用于数据传输,则整体CPU利用率会增加,并影响CPU上的其他工作。使用GDS可以降低CPU负载,从而缩短应用程序代码的运行时间。因此,GDS可以避免计算和内存带宽瓶颈。这两个方面都因GDS而得到缓解。一旦数据不再需要经过 CPU 内存的路径,新的可能性就出现了。
- 新的 PCIe 路径:考虑采用两级 PCIe 交换机的系统。NVMe 硬盘连接到第一级交换机,每个 PCIe 树最多可连接四个硬盘。每个 PCIe 树中可能包含两到四个 NVMe 硬盘,它们都连接到第一级交换机。如果使用速度足够快的硬盘,它们几乎可以饱和第一级 PCIe 交换机的 PCIe 带宽。例如,NVIDIA GPUDirect Storage 工程团队在 PCIe Gen 3 设备上,使用 4 个硬盘组成 2x2 RAID 0 配置,测得速度为 13.3 GB/s。在 CPU 控制路径上使用 RAID 0 不会影响直接数据路径。在 NVIDIA DGX™-2 中,八个 PCIe 插槽连接到第二级交换机,这些插槽可以安装网卡或 RAID 卡。在这种 Gen 3 配置中,网卡的实测速度为 11 GB/s,RAID 卡的实测速度为 14 GB/s。从本地存储和远程存储的这两条路径可以同时使用,而且重要的是,整个系统的带宽是累加的。
- PCIe ATS:随着设备增加对 PCIe 地址转换服务 (ATS) 的支持,它们可能不再需要。使用 CPU 的输入输出内存管理单元 (IOMMU) 进行虚拟化所需的地址转换。由于不需要 CPU 的 IOMMU,因此可以采用直接路径。
- 容量和成本:当数据通过 CPU 内存复制时,必须在 CPU 内存中分配空间。CPU内存容量有限,通常在1TB左右,高密度内存价格最高。本地存储容量可达数十TB,远程存储容量可达PB级。磁盘存储比CPU内存便宜得多。对于GDS而言,存储的具体位置并不重要,只要它位于节点内、同一机架内或远在异地即可。
- 内存分配:CPU 缓冲缓冲区需要管理,包括分配和释放。这需要时间和资源。在某些情况下,缓冲区管理可能会影响性能。如果没有 CPU 反弹缓冲区,则可以避免这种管理开销。当 CPU 不需要反弹缓冲区时,系统内存就可以释放出来用于其他用途。
- 可迁移内存: CPU 和 GPU 之间来回迁移内存早已成为可能
cudaMallocManaged。近年来,基于 x86 系统的异构内存管理 (HMM) 以及 Grace Hopper 一代 CPU 和 GPU 的集成,使得支持可位于任何位置的缓冲区目标变得更加重要。从 CUDA 12.2 开始,GDS 支持以任何类型的分配方式来定位缓冲区,无论是仅限 CPU 分配还是可在 CPU 和 GPU 之间迁移。 - 异步性:虽然最初的 cuFile API 不是异步的,但 CUDA 12.2 中增强的 API 添加了 CUDA 流参数,从而实现了异步提交和执行。
3 CuFile API
应用程序和框架开发者通过集成 cuFile API 来启用 GPUDirect 存储功能。应用程序可以直接使用 cuFile API,也可以利用 RAPIDS 或 DALI 等框架以及 C++ 或 Python 等更高级别的 API。cuFilevikio提供同步和异步 API。同步 API(例如cuFileRead、cuFileWrite、pread 和 pwrite)支持类似于 POSIX pread 和 pwrite 的读写操作,并带有 O_DIRECT 属性。cuFile 批处理 API 提供类似于 Linux AIO 的异步 I/O 执行。从 CUDA 12.2 版本开始,cuFile 流 API 支持在 CUDA 流中异步提交数据,并支持类似于 Linux AIO 的异步执行。此外,cuFile 还提供用于驱动程序初始化、终结、缓冲区注册等的 API。基于 cuFile 的 I/O 传输是显式且直接的,从而能够实现最佳性能。