FlexGen论文阅读
本文为论文 FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU 的阅读笔记。
摘要
大语言模型推理需要高计算和内存资源,通常依赖多块GPU。但在对延迟不敏感、可批量处理的应用中,存在在资源有限设备(如单张普通GPU)上实现高吞吐量推理的需求。
论文提出 FlexGen:一种为资源受限环境设计的高吞吐量LLM推理引擎。FlexGen 可在不同硬件约束下运行,通过聚合 GPU、CPU 和磁盘的内存与计算资源来支持大模型推理。使用线性规划算法搜索最优张量存储与访问模式,从而提高效率。对模型的权重和注意力缓存进行4-bit量化压缩,在几乎不影响精度的前提下减少内存使用。
在仅有一张16GB显存的GPU上运行OPT-175B模型,FlexGen首次实现了1 token/s 的生成速度,支持 144的有效 batch size,大幅超越已有的卸载系统。
1 研究背景
1.1 研究背景与动机
大语言模型的能力与挑战并存:近年来,LLMs(如 GPT、PaLM、OPT)在多个任务上表现出色,但推理过程的计算和内存需求(模型参数、KV 缓存等)极高。如 GPT-175B 模型需要 325GB GPU 显存才能加载,仅加载模型就需至少 5 张 A100 (80GB) GPU 并搭配复杂的并行策略。
研究场景定位:除了实时交互场景(如聊天机器人),LLMs 还被应用于延迟不敏感的后台任务,例如基准测试、信息抽取、数据整理、表单处理等,这些任务通常对延迟要求低,但处理规模大,更关注每秒能处理多少 token(吞吐量)。
基本思路:在此类场景中,可以用较大 batch size 换取吞吐量,并摊平 I/O 开销,实现资源节约。
1.2 已有方法与不足
三类主流方法:
- 模型压缩(如量化、剪枝)以减少内存占用;
- 协同推理,借助多个设备协作来分担负载;
- 模型卸载,将部分模型或中间结果从GPU转移至CPU或磁盘。(例如 DeepSpeed Zero-Inference、Hugging Face Accelerate)
不足之处:
- 这些系统大多面向低延迟推理,假设用户拥有高端加速硬件(如 A100、H100)。它们对吞吐量优化或普通硬件(如 T4 或无 GPU)缺乏支持。
- 前两种方法通常仍需模型整体常驻GPU内存,难以支持像 OPT-175B 这样的大模型在单GPU上运行。
- 第三种(卸载)虽然适用于低资源环境,但现有方案存在I/O调度和张量放置效率低的问题,导致吞吐量受限。多数继承了训练阶段的卸载方法,忽视了生成式推理的特殊计算结构(例如 KV Cache 只读、计算依赖较弱等),因此I/O调度效率低下。举例:现有系统在推理 OPT-175B 时,batch size 有时仅为 1–2,远低于可接受范围。
Petals:一种协同计算的新思路,提出了一种 协同式去中心化 LLM 推理方法,通过多个低端设备协作完成推理任务,缓解了本地硬件不足问题。但 Petals 主要解决的是 硬件分布性,而非 I/O 或单机效率。
1.3 研究目标与策略
核心目标:在单张普通GPU(如16GB显存的T4)上,实现高吞吐量的 LLM 生成式推理。
策略框架:利用三层内存层级(GPU / CPU / 磁盘)的差异进行设计。通过大批量推理来摊销慢速I/O的开销,并与计算过程并行化。
主要技术挑战:
高效卸载策略设计:推理中涉及三种张量:权重、激活值、KV缓存。必须决定:哪些张量要卸载、卸载到哪里(GPU/CPU/磁盘)、何时卸载。推理过程呈现逐batch、逐token、逐层的复杂依赖图,形成极大的策略搜索空间。现有方法通常延用训练阶段的卸载策略,但这些策略对推理阶段并不高效,I/O冗余严重,吞吐量低。
高效压缩策略设计:尽管已有研究在权重和激活值压缩方面取得成果,但在与卸载结合的高吞吐推理场景中,还需进一步优化:特别是对权重和KV缓存的I/O与内存占用需要进一步压缩。
1.4 FlexGen贡献
- 提出新的卸载策略搜索空间:将模型执行划分为三个维度:计算顺序、张量放置(在哪个设备存储)、计算委托(交给谁执行)。证明其搜索空间中的最佳策略,I/O复杂度为 2× optimality。
- 设计线性规划搜索算法:能根据硬件资源(如GPU显存、CPU内存、SSD带宽等)优化吞吐量。可灵活调整以支持不同的延迟和吞吐需求,在延迟与吞吐之间做出权衡。
打破 batch size 上限瓶颈:统一调度权重、激活值和 KV cache 的放置,显著提升可用的最大 batch size,是提升吞吐量的关键。
- 4-bit 精度压缩技术:对模型权重和 KV cache 进行 4-bit 压缩,几乎无准确率损失。
2 FlexGen卸载策略
2.1 问题定义
目标:通过卸载策略,在多层内存系统(GPU/CPU/磁盘)中高效调度推理任务,解决大模型无法完全装入 GPU 的问题。
推理卸载问题建模:图遍历模型
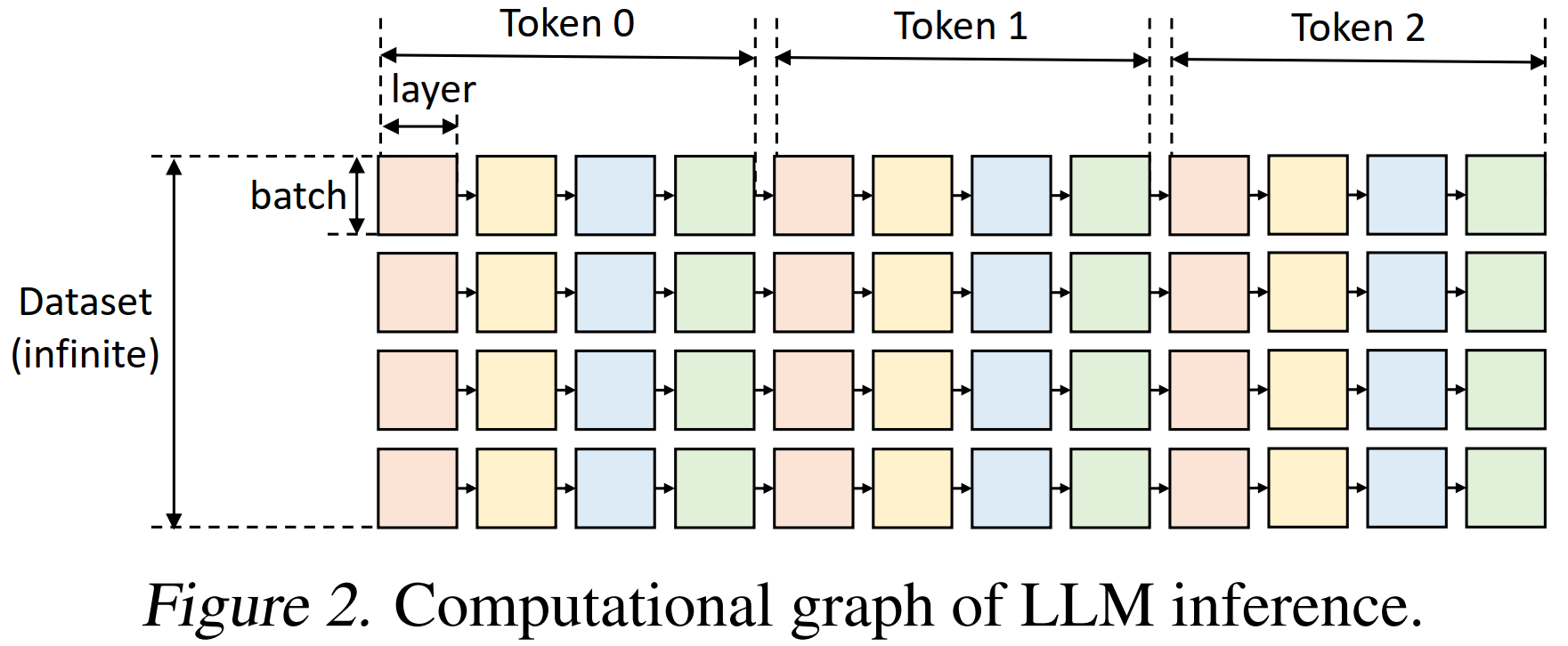
图模型描述:
- 节点表示每一层在某个 token 时间步上的一次 GPU batch 计算。同一颜色的节点表示使用相同的模型层参数。每个方块的计算依赖于:前一个 token 步的输出、所需的模型权重、激活值和 KV 缓存。
图遍历的有效路径约束:
- 只有当左侧同一行的方块都已被计算,当前方块才可以被计算(token 生成是顺序的)。
- 要在某个设备上计算一个方块,其所有依赖项(权重、激活、KV 缓存)必须在该设备上。
每次计算会产生两个输出:激活值要保留到右侧相邻 token 的计算完成,KV 缓存要保留到该层最右侧 token 完成。
- 每个设备上存储的所有张量总量不能超过内存上限。
优化目标:找到一条有效的路径,最小化总执行时间,包括在设备间移动张量时的计算成本和I/O成本。
2.2 搜索空间
1. 计算调度策略
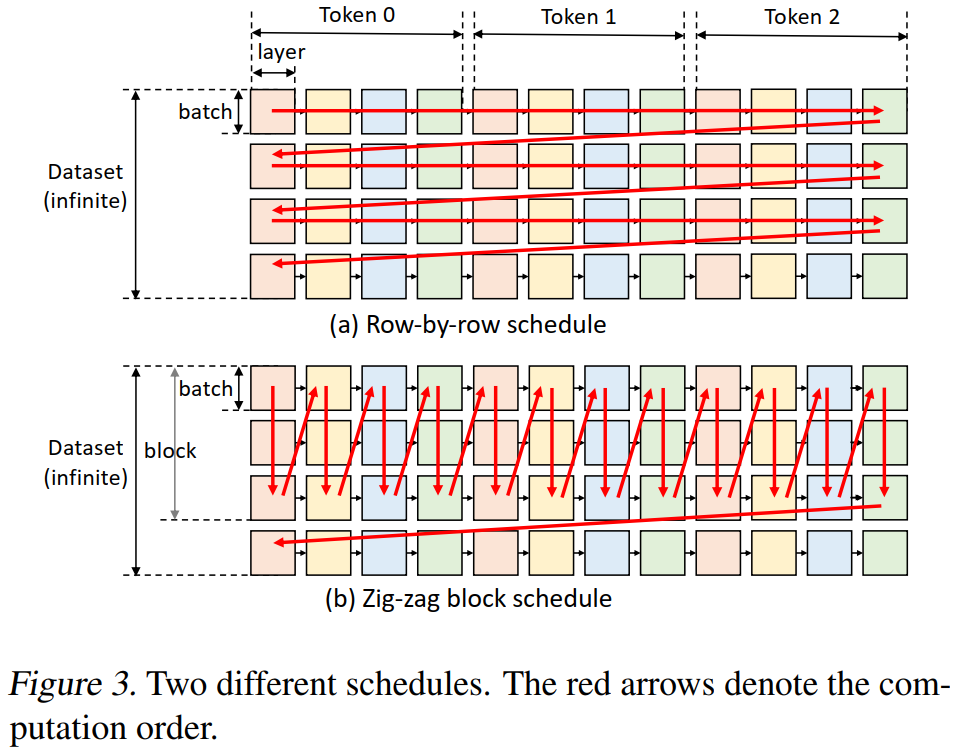
- 行优先遍历:现有系统(如 DeepSpeed、Accelerate)采用行优先策略,优点是能最早完成一个 batch,释放对应层的 KV cache;缺点是两个相邻执行块不共用权重,导致频繁加载,产生大量 I/O 开销。
- 列优先遍历:能让对应层的权重保留在 GPU 上,只需传输激活值和缓存。但列遍历会累积激活值和 KV cache,直到 CPU/磁盘内存耗尽。
- Zig-zag block 调度策略
- 折中方案:沿列方向处理若干 batch,再切换方向,形成“之”字形的块调度方式。
- 可重用权重,控制激活/KV大小,避免内存溢出。理论证明其 I/O 复杂度最多为最优方案的 2 倍。
- 重叠执行优化
- 进一步通过并行层间权重加载、缓存保存、激活值更新与当前计算,提升效率。
2. 张量放置策略
- 参数用变量控制:
wg, wc, wd分别表示 权重存放在 GPU、CPU、disk 的比例。hg, hc, hd定义 激活值 activations 比例,cg, cc, cd定义 KV cache 比例。 粒度选择:
- 权重采用层粒度:判断每层模型放在哪。
- 激活值与 KV cache采用张量粒度:更细粒度,可分割 tensor 元素。
- 权衡:层粒度开销低但限制多,张量粒度更灵活,适合优化 I/O。
3. 计算委托策略
虽然 GPU 更快,作者指出在某些场合,将注意力分数计算委托给 CPU 执行更高效。如果 KV cache 存在于 CPU 层,在 GPU 执行需将KV cache传回GPU,I/O 开销极大;而将 attention score 计算任务移到 CPU,只需要将小得多的激活值传输给 CPU,极大降低 I/O。
因此对于长序列,若 KV cache 不在 GPU,CPU 计算 attention 是更优策略。
2.3 成本模型和策略搜索
1. 成本模型
- 一个 block 的总延迟:$T = T_{\text{pre}} \cdot l + T_{\text{gen}} \cdot (n - 1) \cdot l$
- $T_{\text{pre}}$:预填阶段中每层的延迟,$T_{\text{gen}}$:解码阶段中每层的平均延迟
- 在 假设完美流水并行重叠 的前提下,预填和解码延迟取决于五类操作中的最大值。例如:$T_{\text{pre}} = \max(ctog^p, gtoc^p, dtoc^p, ctod^p, comp^p)$
2. 策略搜索
- 策略变量(共11个)
- 执行参数:
bls一次运行多少 token、gbs(GPU batch size) - 张量放置参数:权重位置:
wg, wc, wd、激活值位置:hg, hc, hd、KV Cache 位置:cg, cc, cd
- 执行参数:
- 两阶段优化方法
- 离散枚举
(bls, gbs)。gbs通常为 4 的倍数,bls小于 20(搜索空间有限) - 固定
(bls, gbs)后,进行线性规划。只有 9 个变量,该线性规划问题可以非常高效地求解。 - 目标函数:$\min_p \frac{T}{\text{bls}}$
- 离散枚举
2.4 扩展到多GPU
两种主流模型并行方法:
- Tensor Parallelism:将每一层的张量操作在多个 GPU 上并行执行。能够 减少单个查询的延迟。通信成本较高,吞吐量扩展性较差。
- Pipeline Parallelism:将整个模型(如一个 l 层的大语言模型)按层划分到多个 GPU 上,每个 GPU 执行其中的 l/m 层。GPU 按照 流水线方式并行运行。通信开销较低,吞吐量扩展性较好。更适合 FlexGen。
FlexGen 实施方式:将一个 l 层的大语言模型 平均划分到 m 个 GPU 上,每个 GPU 执行 l/m 层。每个 GPU 上运行的就是一个 简化版模型(n/m 层),可以复用单 GPU 的策略搜索算法。
3 FlexGen近似方法
1. Group-wise Quantization(组级量化)
目的:压缩权重和 KV 缓存,降低 I/O 成本和内存占用,而不是像以往工作那样主要用于加速整数矩阵乘法。
方法细节:
不需要重新训练或校准,即可将 OPT-175B 的权重和 KV 缓存量化为 4-bit 整数,且几乎无精度损失
使用 细粒度组级非对称量化,具体步骤:将张量按某一维度划分为多个连续的 group,每组有 g 个元素。对每组分别计算最小值
min和最大值max。采用公式将每个元素 x 量化为 b 位整数:$x_quant = round(\frac{x - min}{max - min} × (2^b - 1))$。量化后的张量存储在压缩格式中,在计算前再还原为 FP16。
- 分组策略选择:对于权重,在输出通道维度上分组效果最好。对于 KV 缓存,在 隐藏维度上分组最有效。
- 注意事项:虽然该方法减少了 I/O 和内存占用,但 在 CPU 上解压缩开销较大,因此启用量化时禁用 CPU offloading。
2. Sparse Attention(稀疏注意力)
目标:进一步减少 KV 缓存加载开销,通过稀疏化自注意力机制,仅加载对推理效果影响最大的部分缓存。
- 实现一个简单的 Top-K 稀疏注意力近似算法:在计算注意力矩阵后,对于每一个查询:找出它在 KV 缓存中的前 K 个最相关 token。丢弃其余部分,仅加载与这些 token 相关的 V 缓存数据。
- 效果:在 OPT-175B 上,仅加载 Top 10% 的注意力缓存即可保持模型质量不变。
两种近似技术都可以在保持高精度的同时大幅提升推理效率。量化主要减少 I/O 和内存占用,稀疏注意力减少了推理时对缓存的访问量。
4 实验
- 模型:OPT 系列模型(6.7B ~ 175B)。
- 对比基线系统
- DeepSpeed ZeRO-Inference:支持将整个模型权重 offload 到 CPU 或磁盘。支持多 GPU。使用逐行执行调度。仅支持将缓存 / 激活放在 GPU 上。
- Hugging Face Accelerate:仅支持部分权重 offload。不支持跨机器的多 GPU。也使用逐行调度。
- Petals:属于“去中心化协同推理”方案。能降低单机资源需求,因此也作为对比基线。

1. 最大吞吐量评测
使用 单 GPU 评估三种模型(OPT-6.7B / 30B / 175B)在两种 prompt 长度下的最大生成吞吐量。
结果:
OPT-6.7B:Accelerate 和 FlexGen 可以完全将模型加载进 GPU。DeepSpeed 内存开销大,无法加载进 GPU,只能使用较慢的 CPU offloading。FlexGen 与 Accelerate 性能相当,但比 DeepSpeed 明显更快。
OPT-30B:所有系统都需使用 CPU offloading。DeepSpeed 和 Accelerate 仍将 KV 缓存在 GPU,限制了 batch size。FlexGen 将大部分权重和所有 KV cache offload 到 CPU,支持更大的 GPU batch。FlexGen 通过 block scheduling 重用权重,进一步提升效率。
OPT-175B:所有系统开始使用磁盘 offloading。基线系统最大只能使用 batch size 为 2。FlexGen 可以用 batch size 为 32,block size 为 32 × 8,吞吐量提升 69 倍。开启压缩后(weights 和 KV cache 压缩至 CPU 内存),吞吐量可达 112 倍提升,有效 batch size 为 144。避免磁盘换入换出是吞吐量提升的关键。
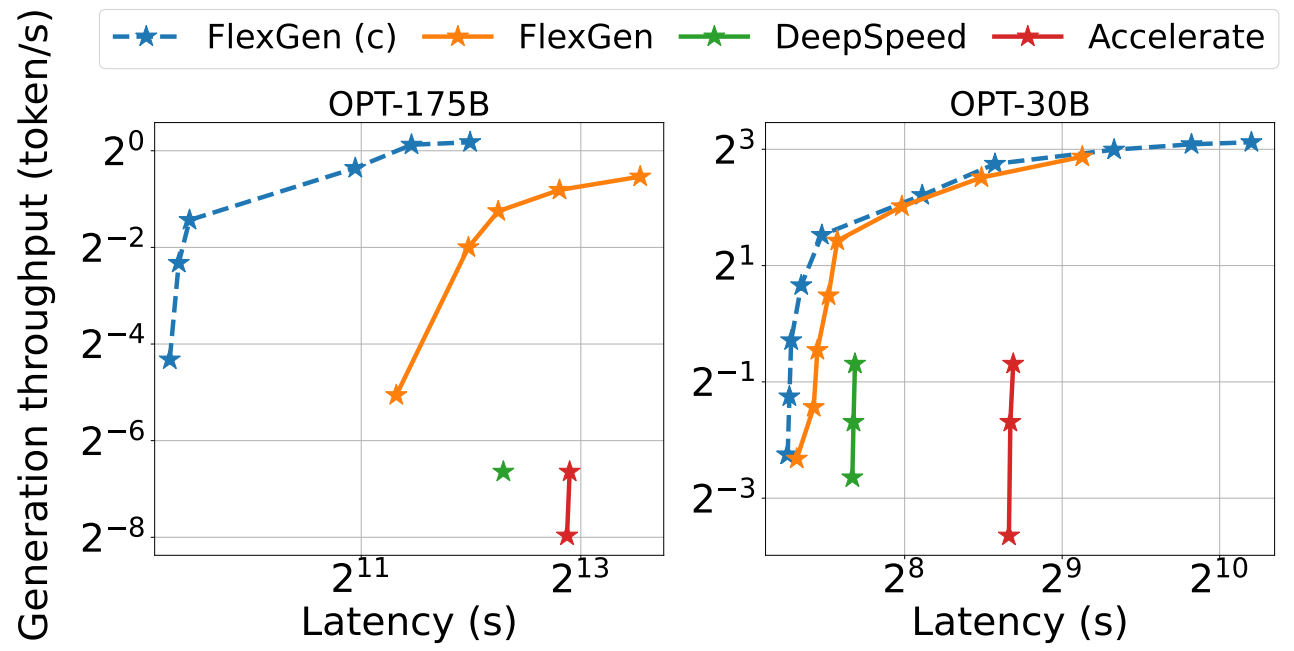
2. 延迟-吞吐量权衡(Latency-Throughput Trade-off)
设定不同延迟限制,绘制各系统的延迟-吞吐量曲线。
结果:
FlexGen 在各点都优于基线系统,形成新的 Pareto 最优边界。低延迟场景:FlexGen 支持部分 offloading,尽可能利用 GPU 空间加载权重。高吞吐场景:FlexGen 激进 offload 所有权重和缓存,以支持更大 GPU batch 和 block。
在延迟限制为 5000s 情况下:FlexGen吞吐量比基线提升 40 倍;使用压缩和高 latency 容忍时,吞吐量可达 100 倍提升。原因:压缩后权重和 KV cache 全部放入 CPU 内存,完全避免慢速磁盘访问。
3. 消融实验
分析每个优化技术对吞吐量的贡献。