3L-Cache 论文阅读
本篇为论文 3L-Cache: Low Overhead and Precise Learning-based Eviction Policy for Web Caches 的阅读笔记。
摘要
1. 问题背景:
缓存可以降低请求延迟和网络流量,而淘汰策略的效果通常用 字节丢失率 和 对象丢失率 来衡量。虽然基于学习的策略能有效降低这两种丢失率,但其高计算开销限制了在实际系统中的应用。
2. 3L-Cache 的创新点:
- 高效的数据收集方案:过滤掉不必要的历史请求,并动态调整训练频率,从而减少计算成本,同时保持准确性。
- 低开销的淘汰策略:结合 双向采样(bidirectional sampling) 来优先淘汰不受欢迎的对象,并设计了一种高效的淘汰机制以精准选择被移除的对象。
- 参数自动调优:提高对不同访问模式的适应性。
3. 实验结果:
- 计算开销大幅降低:相比于 HALP,CPU 开销减少 60.9%;相比于 LRB,减少 94.9%。
- 与 LRU 的对比:小缓存时开销仅为 LRU 的 6.4 倍,大缓存时为 3.4 倍,但在 12 种先进策略中表现最好,达到了 最低的对象丢失率或字节丢失率。
1 研究背景和动机
1.1 缓存的重要性
- 现代缓存系统能够 降低网络流量 和 加快请求响应,例如 Netflix 的 95% 流量都通过缓存提供服务。
- 关键的 淘汰策略 决定哪些数据保留、哪些被移除,其性能由 对象丢失率(object miss ratio) 和 字节丢失率(byte miss ratio) 衡量。
- 降低 miss ratio 可以提升请求处理速度,并减少服务器数据请求量,优化整体性能。
1.2 现有的缓存淘汰策略
1. 理论分析
| 原理 | 例子 | 特点 | |
|---|---|---|---|
| 启发式 | 基于固定规则和对象特征(最近访问、访问频率、对象大小等)做淘汰决策 | LRU/LIRS/LRUK/ARC/CFLRU; LFU/LRFU; LHD/TTL/TinyLFU/DLIRS | 实现简单、效率较高; 稳定性不足,在不同负载未命中率波动较大; |
| 学习型 策略级 | 使用强化学习直接做淘汰决策 | LeCaR/CACHEUS/RL-Cache | 因训练延迟,适应工作负载变化较慢; |
| 学习型 分组级 | 按对象相似性(到达时间等)分组再学习 | GL-Cache | 计算开销低; 受限于分组方法,在部分数据集上表现不佳; |
| 学习型 对象级 | 对每个对象单独训练和预测 | Raven/LRB/HALP/Parrot | 潜力最大,可以在复杂情况下实现最低未命中率; 计算开销高 |
2. 实验分析
- 现有的学习型缓存策略通常只优化某一项指标(对象丢失率、字节丢失率或 CPU 开销),但没有一种策略能在所有三个维度上都表现优秀。
- 对象级学习策略 LRB:字节丢失率最低,对象丢失率较低,但 CPU 开销比 LRU 高出 172 倍(小缓存)。
- 组级学习策略 GL-Cache:对象丢失率最低,但字节丢失率甚至比 LRU 还差,因为它更关注命中请求次数,而非数据量。
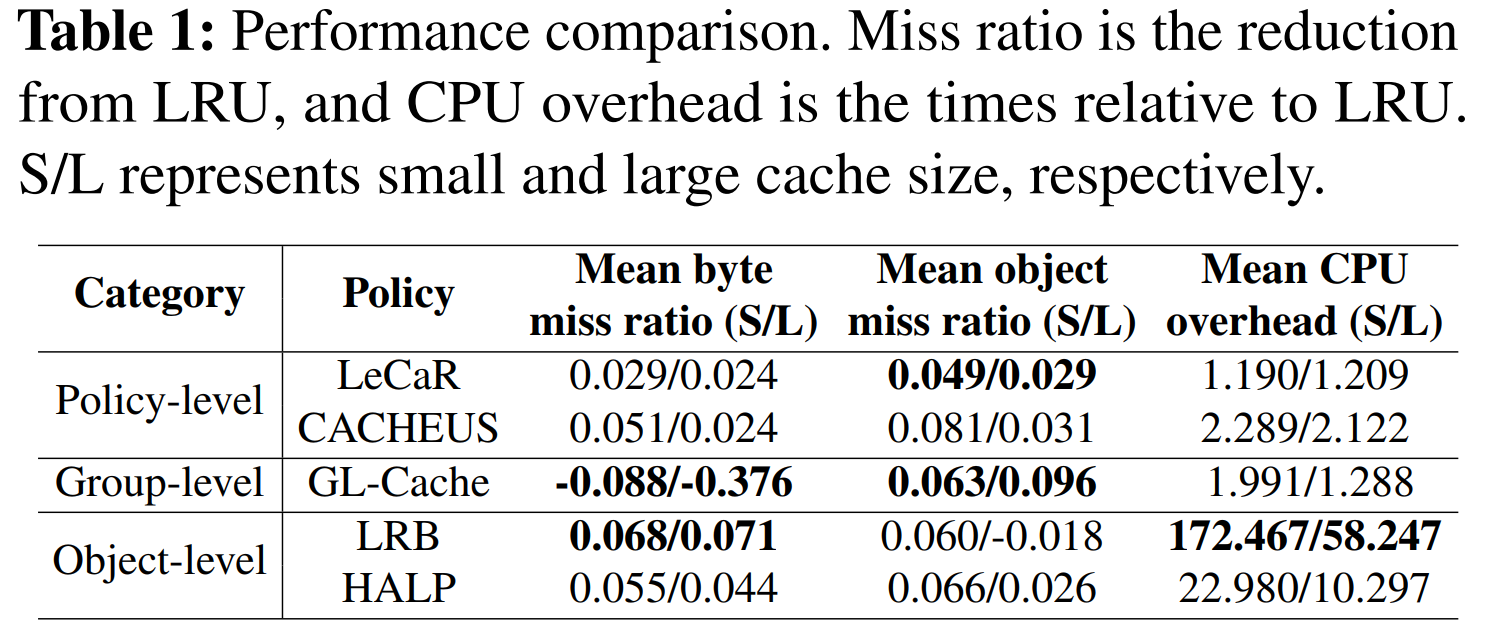
- 对象级学习策略(如 LRB 和 HALP)丢失率低,但CPU 开销过高:
- LRB 的 CPU 开销比 LRU 高出 172 倍(小缓存)、58 倍(大缓存),HALP 也高出 10-23 倍。
- 在 Twitter 和腾讯 CBS 的真实数据集上,这些策略的 CPU 峰值开销都比 LRU 高 10 倍以上,甚至可能达到 300 倍。
- CPU 资源需求波动非常大(最大值和最小值相差 1.5 倍),导致平均 CPU 分配无法满足高峰需求。
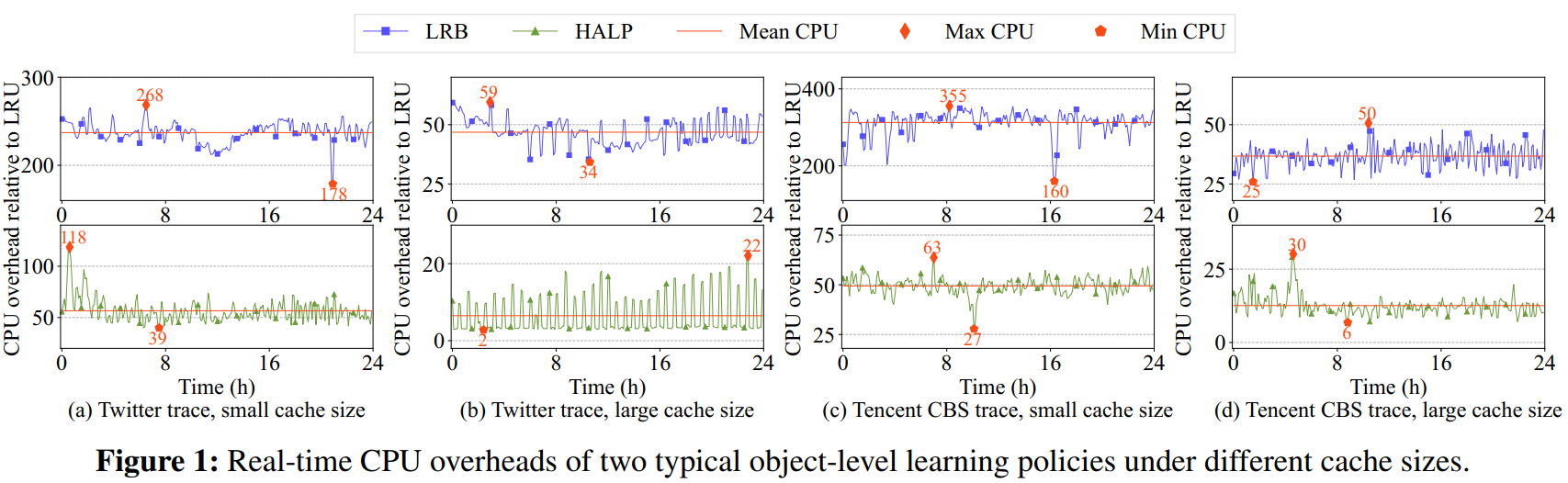
- 总结:由于学习型策略的计算开销过高且波动大,在实际生产环境中难以高效、经济地部署。
1.3 优化空间
1. 计算资源的主要消耗点
- 训练和预测是 CPU 主要消耗来源。
- 小缓存:由于未命中率高,预测频率增加,导致 预测成本占比高。
- 大缓存:未命中率低,预测需求减少,而训练频率不变,导致 训练成本占比高。
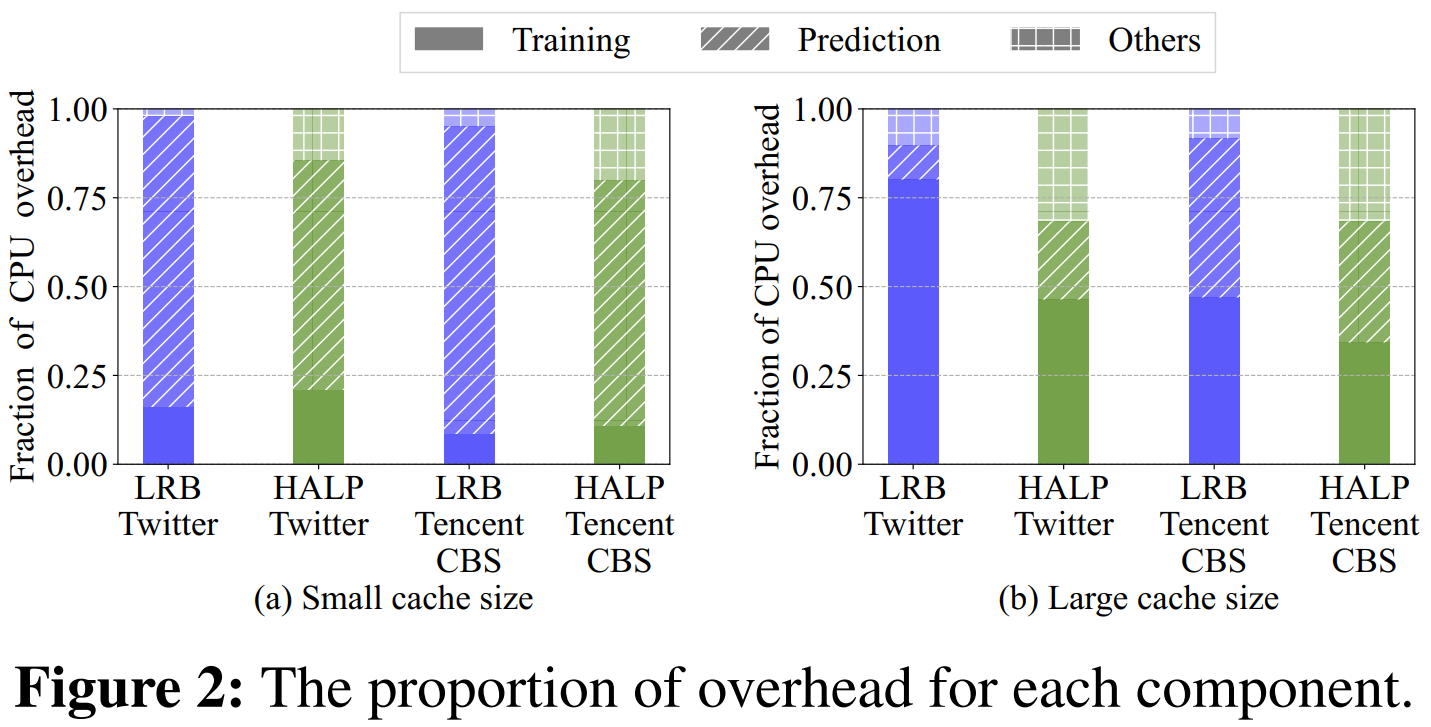
2. 训练成本的优化空间
- 如果 训练频率从 $2^3$ 次/百万请求降到 $2^{-3}$ 次,CPU 开销可减少 48%,而未命中率几乎不变。但如果降到 $2^{-6}$ 次,未命中率会 上升 38%。
3. 预测成本的优化空间
- 预测成本来自 缓存淘汰,即从缓存中选出要删除的对象。
- 关键指标:淘汰比例(Eviction Ratio),即 真正被淘汰的对象数 / 预测候选对象数。
- LRB 每次 随机选 64 个对象 进行预测,但只淘汰 1 个对象,淘汰比例仅 1.56%。
- HALP 只选 4 个对象,淘汰 1 个,淘汰比例 25%。
- 实际生产数据表明 72% 的缓存对象 只被访问过 1 次,意味着可以提高淘汰比例,从而减少预测计算量。
4. 核心挑战
- 如何减少训练的计算开销,而不降低模型准确性?
- 训练频率如果过高,CPU 负担大,但未命中率改善不明显。训练频率如果过低,未命中率会急剧上升。
如何减少预测计算量,而不影响缓存效果?
需要找到高效的采样方式,让淘汰候选对象中包含更多冷数据。、
从候选集中选出最适合删除的对象
- 如何让方法适用于不同的工作负载?
2 3L-Cache
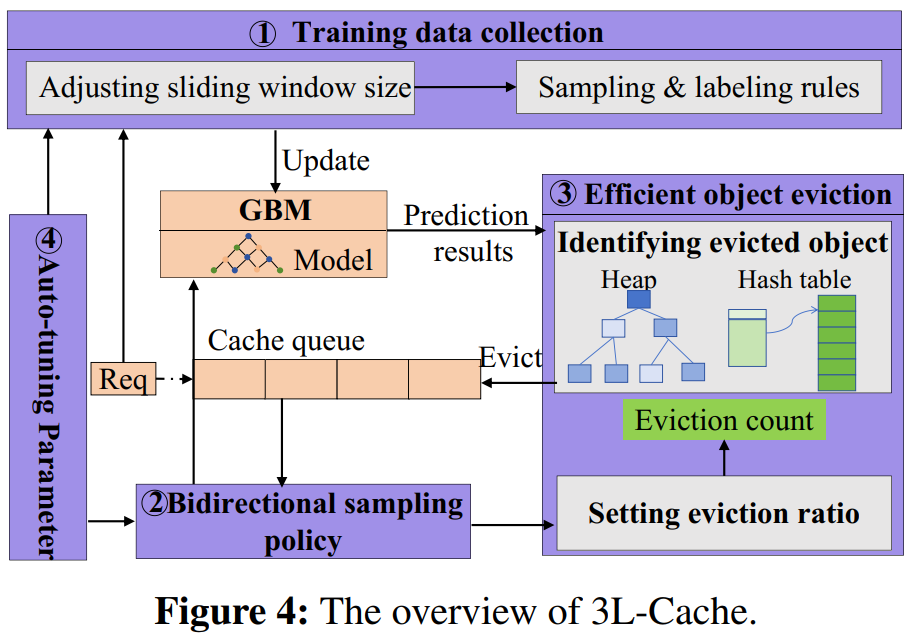
2.1 总体架构
3L-Cache由以下四个核心模块组成:
- Training data collection:决定应该保留多少历史缓存请求数据(滑动窗口大小)
- Bidirectional sampling policy:更精准地找到真正冷门的候选对象
- Efficient object eviction:设定淘汰比例,选择淘汰对象
- Auto-tuning Parameter:自动调整参数,让 3L-Cache 适应不同的场景
3L-Cache 的工作流程:
- 记录历史缓存请求,用于训练机器学习模型(GBM)。
- 当缓存满了,必须腾出空间时:先看当前淘汰计数是否为 0
- 是 0:启动 双向采样策略,计算应该淘汰多少对象,并更新计数。
- 不是 0:直接淘汰“下次访问最远的对象”,然后减少计数。循环以上过程。
- 自动调整参数,确保不同数据模式下都能保持较好的性能。
2.2 在线训练
1. 训练数据收集
两个关键问题:
- 如何选择合适的历史记录窗口大小?
- 太小会导致训练数据不足、模型预测不准;太大会存入过时信息、影响预测效果,增加计算量。
- 如何避免采样到无用的数据?
- 如何选择合适的历史记录窗口大小?
- 历史记录窗口大小
- 窗口的大小等于
hsw × 当前缓存队列大小,其中hsw是一个动态调整的整数。(适应不同缓存需求) - 小缓存需要更大的窗口,因为它主要存放热门对象,而淘汰冷门对象需要更多历史信息来决策。
- 窗口的大小等于
- 数据采样与标签标注
- 采样方法:在滑动窗口中随机选择一个对象,并记录时间。如果一个对象在采样后再次被选中 但还没被新请求访问,那么不会再次记录。(去重机制)
- 标注训练数据:
- 如果采样对象被请求了,就记录它与下一次请求的时间间隔,作为训练标签。
- 如果采样对象很久没被访问,最后被移出窗口,则用它的等待时间 + 训练集中最长的等待时间作为标签。
2. GBM 机器学习模型
- 3L-Cache 使用GBM(梯度提升机)作为预测模型,原因如下:
- 相比 SVM、随机森林、MLP 等,GBM 处理缺失数据的能力更强,不需要额外补全历史特征,计算更高效。过去的研究已经验证 GBM 在缓存预测任务中的表现优异。
模型通过 6 个特征 预测对象的 下次访问时间:
Age:上次被访问后经过的时间。
Size:对象的大小。
Frequency:对象在滑动窗口内被访问的次数。
最近的 3 次访问间隔:如果请求次数不足 3 次,则用 ∞ 填充。
2.3 缓存对象淘汰
为了在不影响缓存命中率的情况下降低淘汰过程的计算开销,需要解决两个关键问题:
- 如何提高待淘汰对象中“不受欢迎对象”的比例?(Bidirectional Sampling Policy)
- 如何具体执行淘汰,包括选取多少个对象以及淘汰哪些对象?(Object Eviction)
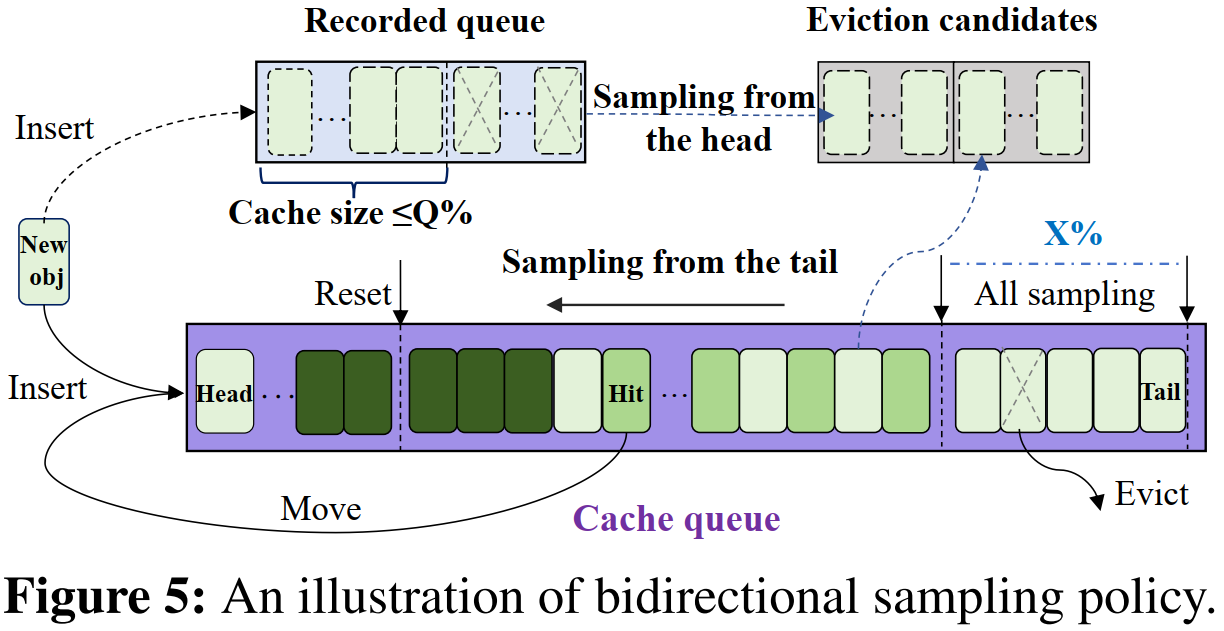
1. 双向采样策略(Bidirectional Sampling Policy)
- 方法:从缓存队列的“头部”和“尾部”同时采样
- 从尾部采样:
- 尾部通常存放不常访问的对象(因为新到的和被访问的对象会插入队列头部)。
- 采样过程:每轮采样 n 个对象,直到扫描的对象总数达到队列长度。尾部 x% 的对象全部采样,其余对象只有访问频率 ≤ f 才会被采样。
从头部采样:
头部包含新到的对象,其中很多可能是不受欢迎的。
采样过程:用一个“记录队列”记录所有新进缓存的对象。如果记录队列占据的缓存空间超过 Q%,则从中选取最久未被访问的对象,直到记录队列占比回到 Q% 以下或采样对象数超过 m。
2. 对象淘汰(Object Eviction)
淘汰比例
- 采用 1:1 的采样比例,分别针对 老旧冷数据(尾部) 和 新进冷数据(头部)。
- 淘汰比例设为50%,即每次淘汰候选对象的一半,避免误删热门对象,并减少计算开销。
选择淘汰对象
- 预测所有候选对象的下次访问时间,选择最长的对象进行淘汰。
高效管理预测数据
- 挑战:每次都要从百万级别的候选对象中找出下次访问时间最长的对象。
- 解决方案:使用最大堆(max heap)+ 哈希表(hash table)管理预测数据,提高查询、插入、修改和删除的效率。
2.4 自动调参
- hsw(滑动窗口大小)
- $\frac{p_s-p_q}{h_{sw}-1} > 0.01·p_q$
- 滑动窗口中未缓存的对象至少需要提供 1%的有效训练样本信息
- $(h_{sw})·(p_s-p_q) < 1-p_q$
- 限制滑动窗口中未缓存对象提供的样本比例,防止无效样本被用于模型训练,降低模型的准确性
- $p_s$是滑动窗口命中率,$p_q$是缓存队列命中率
- $\frac{p_s-p_q}{h_{sw}-1} > 0.01·p_q$
- f(采样阈值)
- 初始值设置为仅挑选访问过一次的对象作为淘汰候选对象,除非有历史数据表明其他对象也应被考虑。
- x(采样范围)和 Q(新对象占比)
- 采样范围以 1% 为单位调整,过低(10%)会导致缓存命中率剧烈波动,而过高(如 0.1%)影响不大。
- 如果 p1 > p2(即前 x% 采样的对象更容易被淘汰),说明 x 需要增大;否则需要减小。
- 如果c1 > c2(从队尾淘汰的对象>从新对象中淘汰的),说明需要淘汰更多队尾的对象,Q加一。否则 Q 减半。
- n(每次采样的对象数量)
- 设定缓存队列中对象数量为 L,n 的上限为 1024,以保证 CPU 计算性能不会成为瓶颈。

3 实验
实验评估主要围绕以下几个问题展开:
- 效果表现:3L-Cache 在字节和对象未命中率上,与最先进的淘汰策略相比表现如何?(3.1)
- 计算开销:3L-Cache 的CPU开销是否与传统启发式方法相当?它在训练和预测过程中的开销降低了多少?(3.2)
- 自动调优能力:3L-Cache 能否自动调整参数,达到最佳性能?(3.3)
- 加速方法的通用性:3L-Cache 的加速技术是否能应用于其他学习型淘汰策略,降低它们的 CPU 开销?(3.4)
- 模拟与原型的一致性:3L-Cache 的原型实现与模拟结果的表现是否一致?(3.5)
实验配置:
- 数据集:使用 8 个公开数据集,总计 4,855 条记录,涵盖 约 14.72 亿对象和 266.95 亿请求,反映各种不同的工作负载情况。
- 比较策略:对比了 12 种最先进的缓存淘汰策略,其中包括 6 种启发式策略(如 LHD、GDSF、ARC、SIEVE、S3-FIFO、TinyLFU)和 6 种基于学习的方法(如 LeCaR、CACHEUS、GL-Cache、LRB、HALP,以及 3L-Cache)。
- 评估指标:
- 未命中率:以字节和对象未命中率与 LRU(基线)相比的降低比例展示。
- 计算开销:以 CPU 使用率相对于 LRU 的倍数来表示。
- 模拟器与原型:
- 模拟器:基于 libCacheSim 库实现
- 原型实现:采用 Python Web 框架和实际 HTTP 请求模拟真实场景,同时监控实时 CPU 使用情况。
3.1 未命中率
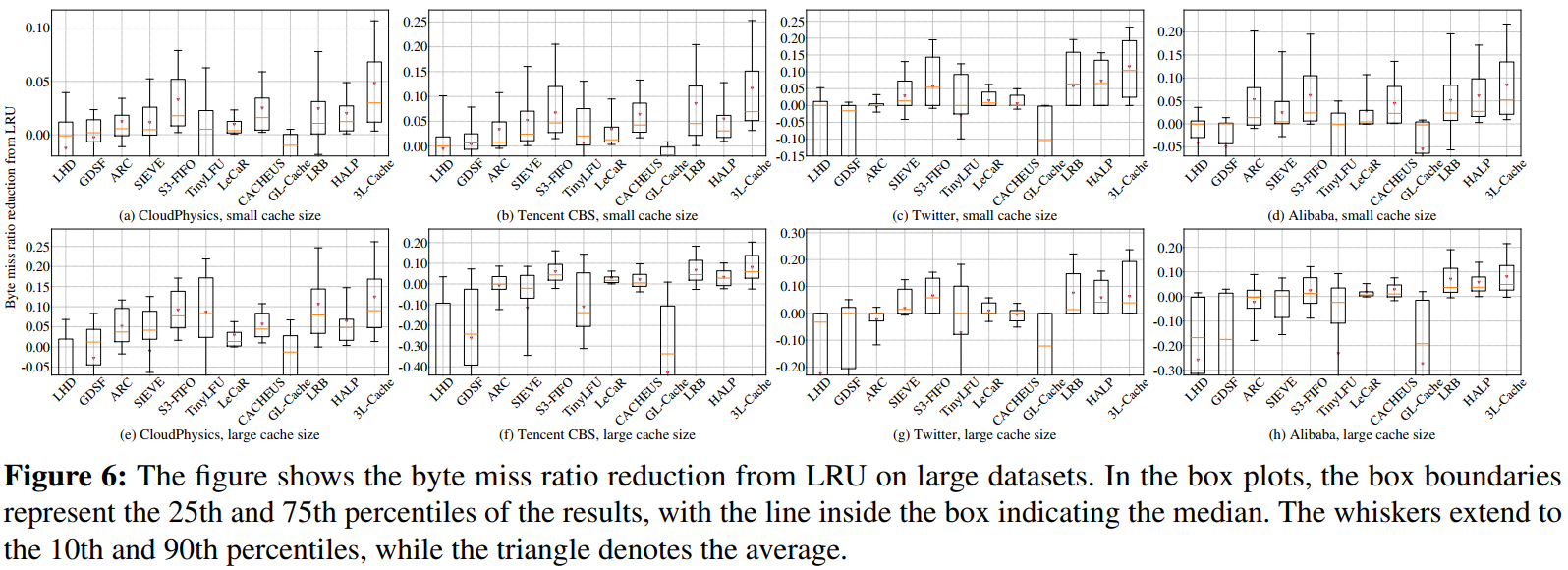
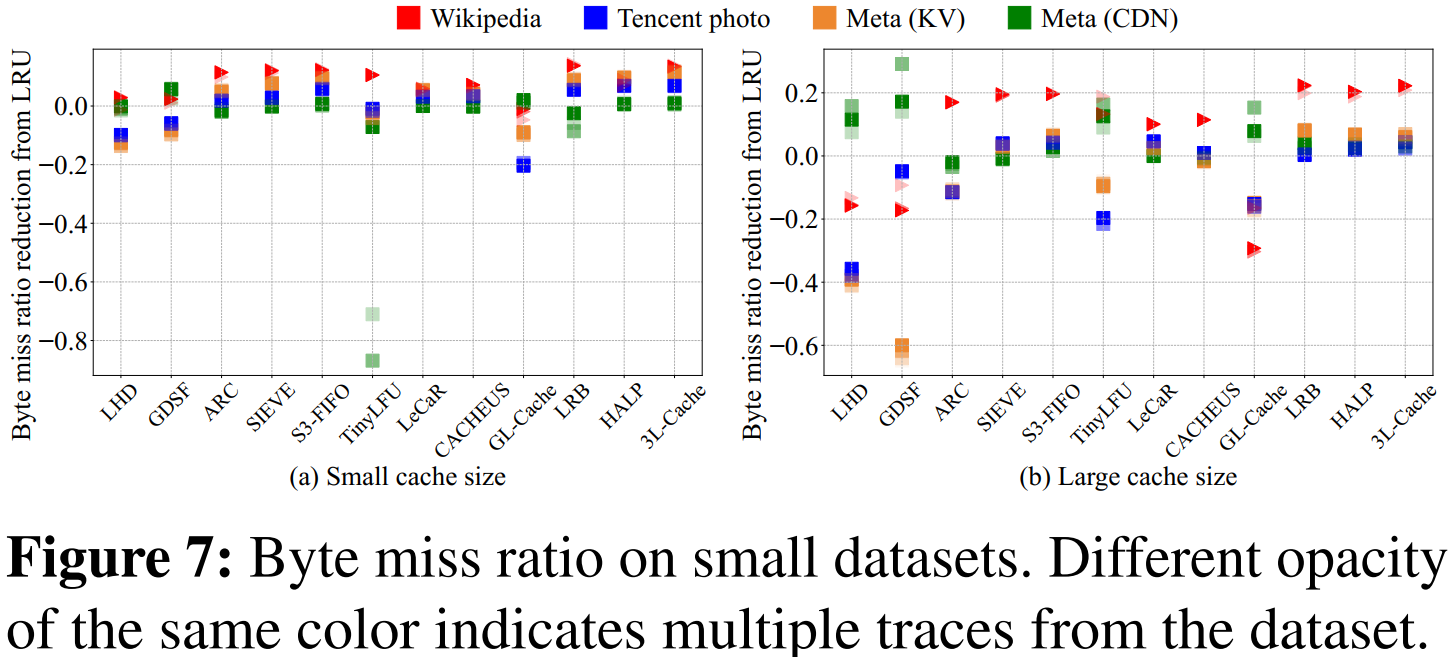
1. 字节未命中率
- 基于对象级学习的策略(如 LRB、HALP、3L-Cache)通常比其他方法效果更好,能大幅降低字节未命中率。
- 3L-Cache 在大多数数据集上表现突出,尤其在处理大规模数据时。在小缓存下,3L-Cache能在近70%的数据轨迹中取得最低的字节未命中率,而在大缓存下也能取得较好的表现,远远超过第二名LRB。
有些策略(比如 GL-Cache)因偏向淘汰小对象而效果较差,有些机器学习方法(LeCaR、CACHEUS)由于依赖预设的启发式策略,其表现也可能不及一些纯启发式方法(如 SIEVE、S3-FIFO)。
- 原因:3L-Cache 采用了更精准的采样策略和累积预测结果,从而能更准确地淘汰真正冷门的对象。
2. 对象未命中率
- 3L-Cache 在小缓存条件下表现较好,能在66%的轨迹中取得最低对象未命中率;但在大缓存条件下,其表现不如某些策略(例如 GDSF 和 LHD)。
对于较大的缓存大小,GDSF 在所有四个数据集上都取得了最佳性能。因为缓存规模大时,缓存对象数量多,LHD 和 3L-Cache 都依赖于基于采样的淘汰,而GDSF 会评估所有缓存对象的淘汰权重。
- 对象级策略在采样淘汰时不仅考虑访问时间,还结合对象大小来决定淘汰顺序,从而使缓存中能保存更多不同的对象,提高命中率。
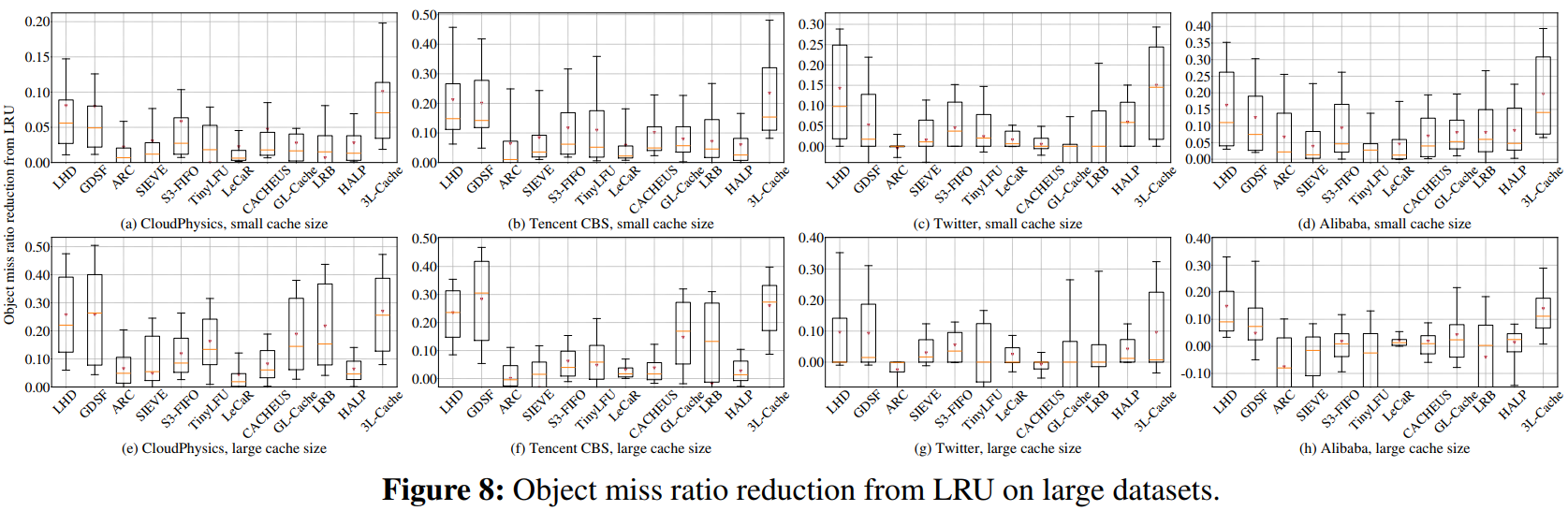
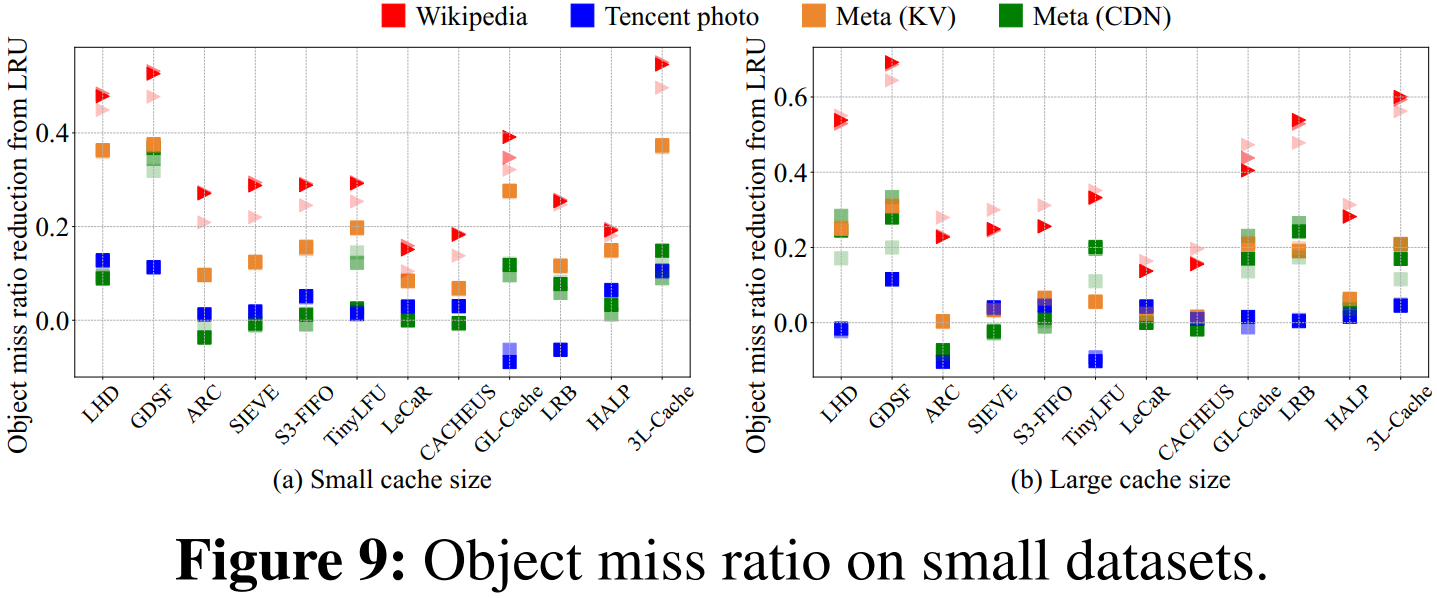
3. 字节与对象未命中率的权衡
- 不同策略的淘汰权重设计各有侧重,有的策略主要侧重降低字节未命中率,而有的则侧重降低对象未命中率。
- 实际应用中,可以根据自己的需求选择最适合的策略。
- 3L-Cache 在两者之间表现较均衡。虽然在部分小数据集上有些策略在某一指标上可能稍好,但 3L-Cache 能保持一致性,避免了某些策略有时反而比 LRU 差的情况。
3.2 CPU开销
1. CPU开销
与其他基于对象级学习的淘汰策略相比,3L-Cache 的 CPU 开销大大减少。例如,相对于 HALP,3L-Cache 平均降低了 60.9% 的 CPU 开销;相比于 LRB,更是降低了 94.9%。
即使和传统的启发式策略(如 LRU、LHD)相比,3L-Cache 的平均 CPU 开销也只有 LHD 的 2.6 倍,LRU 的 6.4 倍左右。
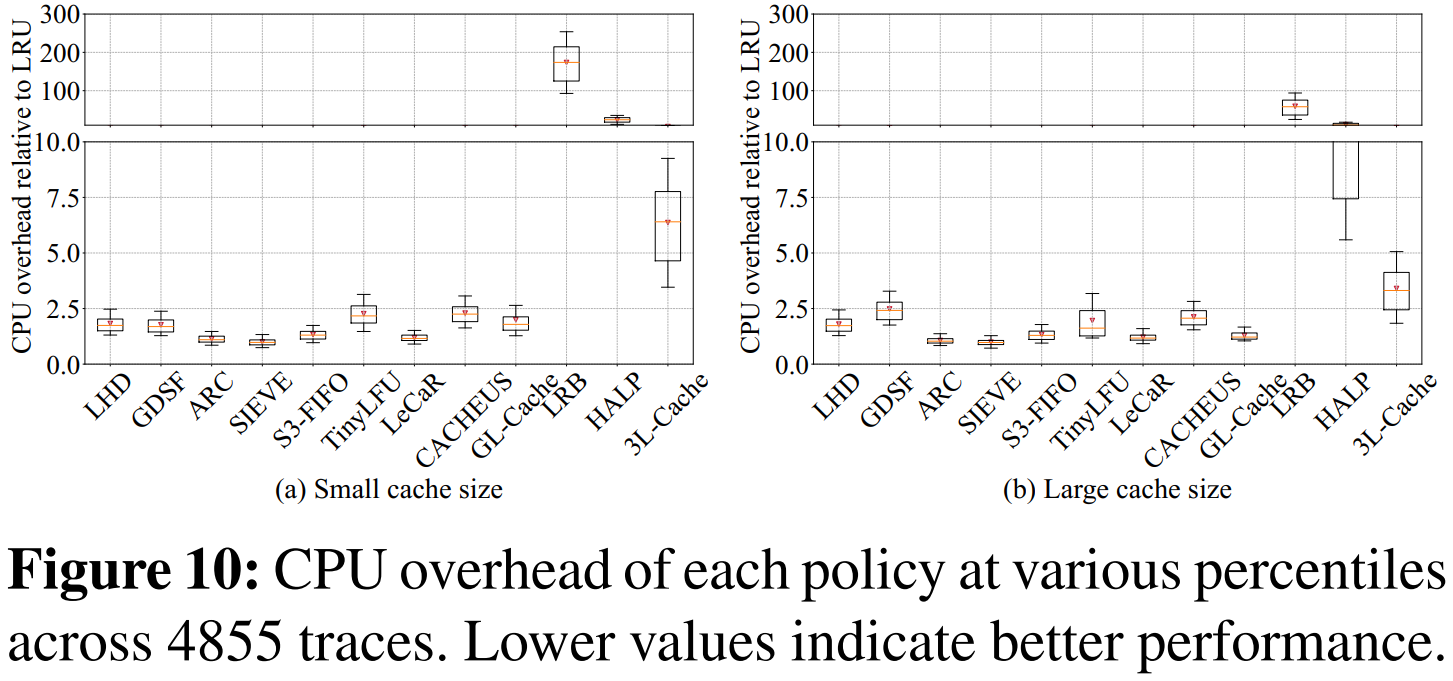
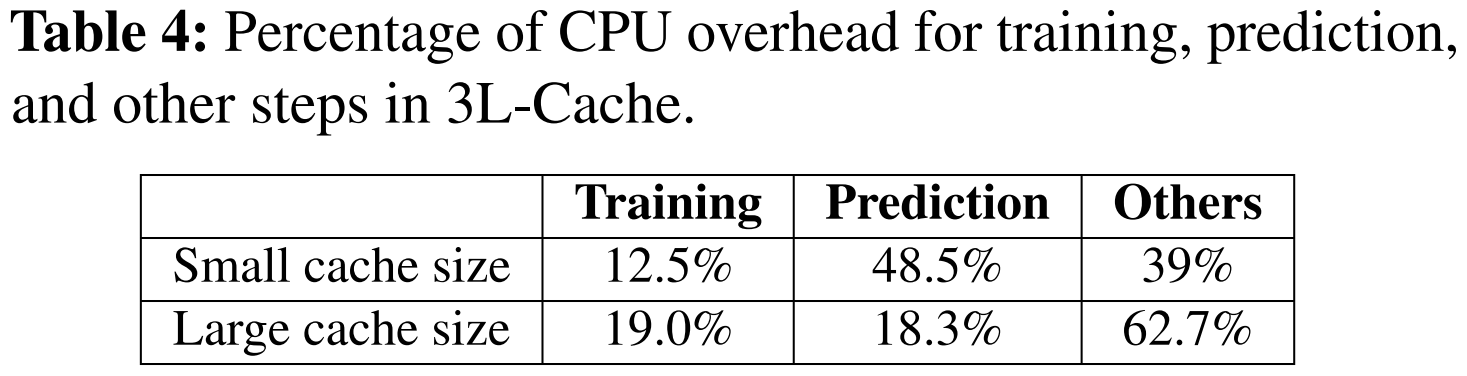
2. 预测和训练开销
- 3L-Cache 主要通过减少预测和训练环节的开销实现低 CPU 占用。
- 在大缓存时,训练和预测开销仅占总 CPU 开销的 37.3%,远低于 HALP 的 64.5% 和 LRB 的 90.9%。
- 3L-Cache 与 LRB 相比,训练开销最多可降低 92.5%,预测开销可降低 98.5%;与 HALP 相比,分别可降低 46.6% 和 85.6%。
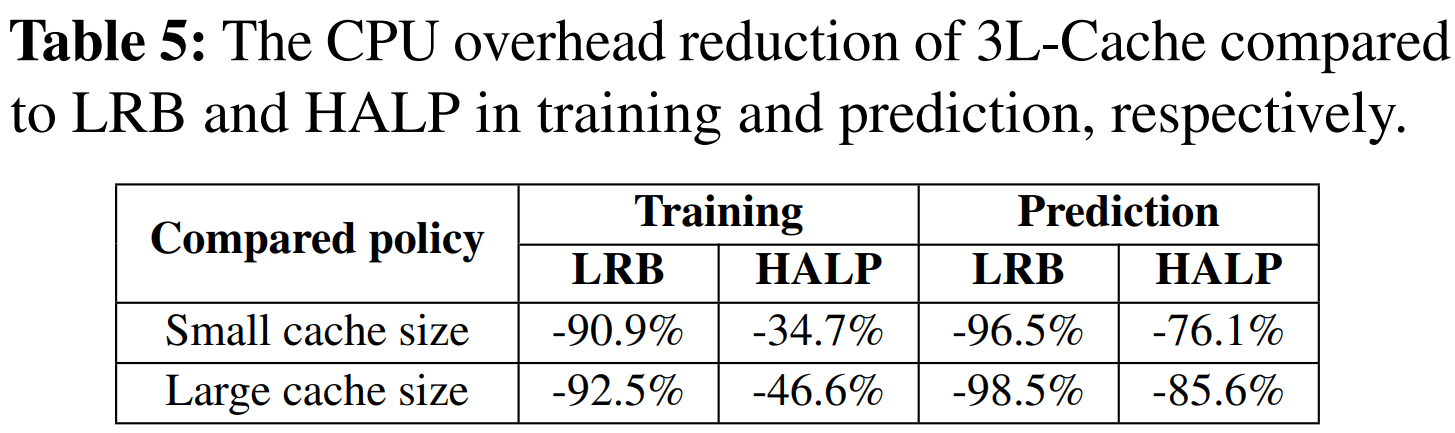
3.3 自动调参
- 对比策略:默认策略、随机调整策略、自动调优策略
- 自动调优策略明显优于其他两种方法。在小缓存环境下,自动调优策略能在 81.6% 的轨迹上达到最佳性能;在大缓存环境下,在 53.6% 的轨迹上表现最佳。
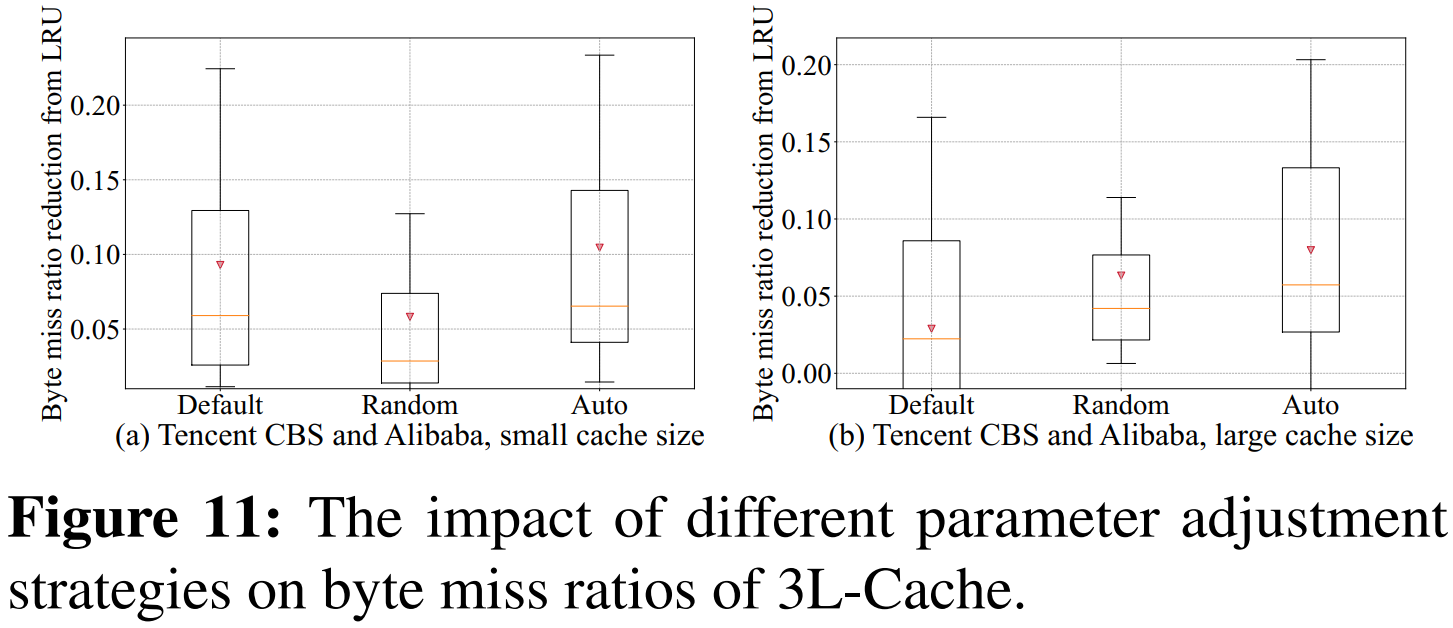
3.4 使用3L-Cache加速LRB
- 改进后LRB的 CPU 开销比原来降低了 80%,但仍高于 3L-Cache。
在降低字节未命中率方面,加速后的 LRB 比原来降低了平均 0.6%,但仍不如 3L-Cache。
- 原因
- 加速后的LRB 主要减少了预测环节的开销,训练开销依然较高;
- LRB 的随机采样容易选中热门对象,而 3L-Cache 的采样策略能更好地避免这一问题
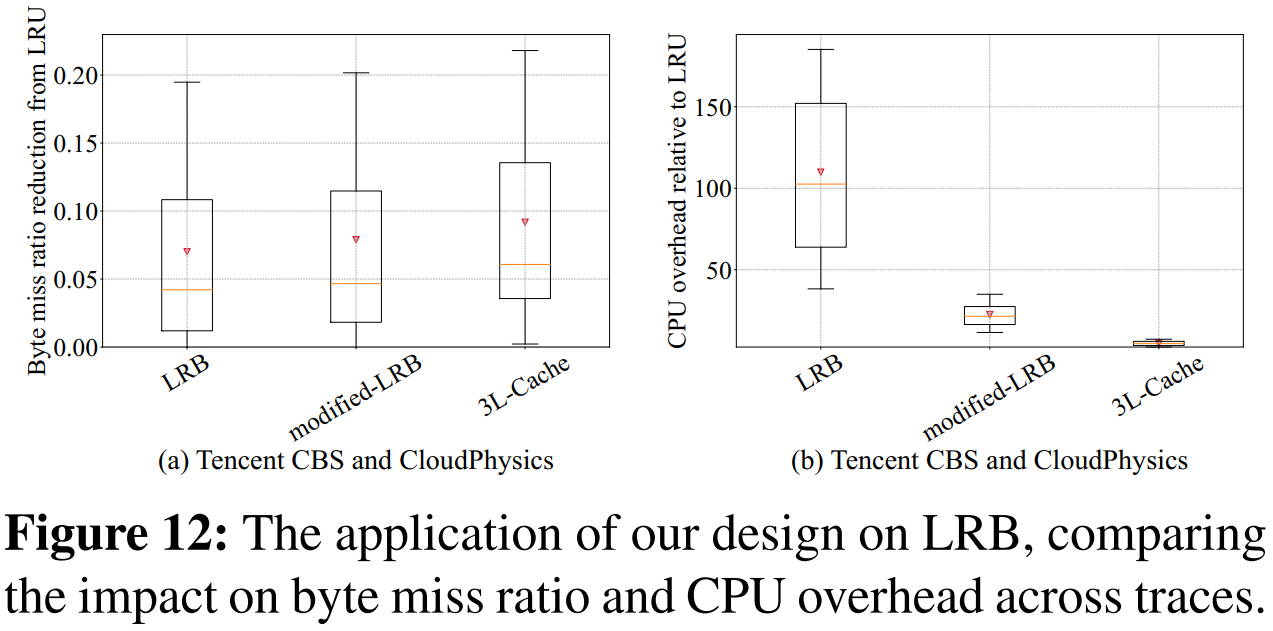
3.5 实际测试
- 字节命中率:原型与模拟结果的差别非常小,误差在 2% 以内。在缓存大小占工作集的 10% 时,原型的字节命中率为 72.6%,而模拟结果为 72.7%。
- CPU 开销:原型的 CPU 开销约为 LRU 的 3 至 6 倍,而模拟实验中约为 5 倍。
- 3L-Cache 的原型在实际部署中能达到与模拟实验相似的性能,验证了其设计的有效性和稳定性。
其他
1. 未来工作
如果某些非典型的网络缓存工作负载不符合 Zipf 分布特点(即访问模式较均匀),3L-Cache 的采样策略可能无法准确区分热门和冷门对象,其效果可能会退化到类似随机采样的水平。因此,未来工作将针对多样化的访问模式设计更高效的淘汰策略,以适应不同生产环境的需求。
2. 论文学习
- 条理清晰:在每章节前面都表明这是解决什么问题的
- 基准测试:工作负载很丰富、实验的类型也很丰富、对结果都解释了背后的原因